publications
Publications in reversed chronological order
2025
- Neuron
 Competitive integration of time and reward explains value-sensitive foraging decisions and frontal cortex ramping dynamicsMichael Bukwich, Malcolm G. Campbell, David Zoltowski, Lyle Kingsbury, Momchil S. Tomov, Joshua Stern, HyungGoo R. Kim, Jan Drugowitsch, and 2 more authorsNeuron, Oct 2025
Competitive integration of time and reward explains value-sensitive foraging decisions and frontal cortex ramping dynamicsMichael Bukwich, Malcolm G. Campbell, David Zoltowski, Lyle Kingsbury, Momchil S. Tomov, Joshua Stern, HyungGoo R. Kim, Jan Drugowitsch, and 2 more authorsNeuron, Oct 2025Patch foraging is a ubiquitous decision-making process in which animals decide when to abandon a resource patch of diminishing value to pursue an alternative. We developed a virtual foraging task in which mouse behavior varied systematically with patch value. Behavior could be explained by models integrating time and rewards antagonistically, scaled by a slowly varying latent patience state. Describing a mechanism rather than a normative prescription, these models quantitatively captured deviations from optimal foraging theory. Neuropixels recordings throughout frontal areas revealed distributed ramping signals, concentrated in the frontal cortex, from which multiple integrator models? decision variables could be decoded equally well. These signals reflected key aspects of decision models: they ramped gradually, responded oppositely to time and rewards, were sensitive to patch richness, and retained memory of reward history. Together, these results identify integration via frontal cortex ramping dynamics as a candidate mechanism for solving patch-foraging problems.
@article{Bukwich2025, author = {Bukwich, Michael and Campbell, Malcolm G. and Zoltowski, David and Kingsbury, Lyle and Tomov, Momchil S. and Stern, Joshua and Kim, HyungGoo R. and Drugowitsch, Jan and Linderman, Scott W. and Uchida, Naoshige}, title = {Competitive integration of time and reward explains value-sensitive foraging decisions and frontal cortex ramping dynamics}, year = {2025}, month = oct, day = {15}, doi = {10.1016/j.neuron.2025.07.008}, volume = {113}, issue = {20}, pages = {3458--3475.e12}, url = {https://doi.org/10.1016/j.neuron.2025.07.008}, journal = {Neuron}, publisher = {Elsevier}, } - bioRxiv
 Distributed control circuits across a brain-and-cord connectomeAlexander Shakeel Bates, Jasper S Phelps, Minsu Kim, Helen H Yang, Arie Matsliah, Zaki Ajabi, Eric Perlman, Kevin M Delgado, and 84 more authorsbioRxiv, Oct 2025
Distributed control circuits across a brain-and-cord connectomeAlexander Shakeel Bates, Jasper S Phelps, Minsu Kim, Helen H Yang, Arie Matsliah, Zaki Ajabi, Eric Perlman, Kevin M Delgado, and 84 more authorsbioRxiv, Oct 2025Just as genomes revolutionized molecular genetics, connectomes (maps of neurons and synapses) are transforming neuroscience. To date, the only species with complete connectomes are worms and sea squirts (103-104 synapses). By contrast, the fruit fly is more complex (108 synaptic connections), with a brain that supports learning and spatial memory and an intricate ventral nerve cord analogous to the vertebrate spinal cord. Here we report the first adult fly connectome that unites the brain and ventral nerve cord, and we leverage this resource to investigate principles of neural control. We show that effector cells (motor neurons, endocrine cells and efferent neurons targeting the viscera) are primarily influenced by local sensory cells in the same body part, forming local feedback loops. These local loops are linked by long-range circuits involving ascending and descending neurons organized into behavior-centric modules. Single ascending and descending neurons are often positioned to influence the voluntary movement of multiple body parts, together with endocrine cells or visceral organs that support those movements. Brain regions involved in learning and navigation supervise these circuits. These results reveal an architecture that is distributed, parallelized and embodied (tightly connected to effectors), reminiscent of distributed control architectures in engineered systems
@article{Bates2025, author = {Bates, Alexander Shakeel and Phelps, Jasper S and Kim, Minsu and Yang, Helen H and Matsliah, Arie and Ajabi, Zaki and Perlman, Eric and Delgado, Kevin M and Osman, Mohammed Abdal Monium and Salmon, Christopher K and Gager, Jay and Silverman, Benjamin and Renauld, Sophia and Collie, Matthew F and Fan, Jingxuan and Pacheco, Diego A and Zhao, Yunzhi and Patel, Janki and Zhang, Wenyi and Serratosa Capdevilla, Laia and Roberts, Ruairi JV and Munnelly, Eva J and Griggs, Nina and Langley, Helen and Moya-Llamas, Borja and Maloney, Ryan T and Yu, Szi-chieh and Sterling, Amy R and Sorek, Marissa and Kruk, Krzysztof and Serafetinidis, Nikitas and Dhawan, Serene and Stuerner, Tomke and Klemm, Finja and Brooks, Paul and Lesser, Ellen and Jones, Jessica M and Pierce-Lundgren, Sara E and Lee, Su-Yee and Luo, Yichen and Cook, Andrew P and McKim, Theresa H and Kophs, Emily C and Falt, Tjalda and Negron Morales, Alexa M and Burke, Austin and Hebditch, James and Willie, Kyle P and Willie, Ryan and Popovych, Sergiy and Kemnitz, Nico and Ih, Dodam and Lee, Kisuk and Lu, Ran and Halageri, Akhilesh and Bae, J. Alexander and Jourdan, Ben and Schwartzman, Gregory and Demarest, Damian D and Behnke, Emily and Bland, Doug and Kristiansen, Anne and Skelton, Jaime and Stocks, Tom and Garner, Dustin and Salman, Farzaan and Daly, Kevin C and Hernandez, Anthony and Kumar, Sandeep and Consortium, The BANC-FlyWire and Dorkenwald, Sven and Collman, Forrest and Suver, Marie P and Fenk, Lisa M and Pankratz, Michael J and Jefferis, Gregory SXE and Eichler, Katharina and Seeds, Andrew M and Hampel, Stefanie and Agrawal, Sweta and Zandawala, Meet and Macrina, Thomas and Adjavon, Diane-Yayra and Funke, Jan and Tuthill, John C and Azevedo, Anthony and Seung, H. Sebastian and de Bivort, Benjamin L and Murthy, Mala and Drugowitsch, Jan and Wilson, Rachel I and Lee, Wei-Chung Allen}, title = {Distributed control circuits across a brain-and-cord connectome}, elocation-id = {2025.07.31.667571}, year = {2025}, doi = {10.1101/2025.07.31.667571}, publisher = {Cold Spring Harbor Laboratory}, url = {https://www.biorxiv.org/content/early/2025/08/01/2025.07.31.667571}, journal = {bioRxiv}, } - bioRxiv
 A unifying theory of receptive field heterogeneity predicts hippocampal spatial tuningZach Cohen, and Jan DrugowitschbioRxiv, Oct 2025
A unifying theory of receptive field heterogeneity predicts hippocampal spatial tuningZach Cohen, and Jan DrugowitschbioRxiv, Oct 2025Neural populations exhibit receptive fields that vary in their sizes and shapes. Despite the prevalence of such tuning heterogeneity, we lack a unified theory of its computational benefits. Here, we present a framework that unifies and extends previous theories, finding that receptive field heterogeneity generally increases the information encoded in population activity. The information gain depends on heterogeneity in receptive field size, shape, and on the dimensionality of the encoded quantity. For populations encoding two-dimensional quantities, such as place cells encoding allocentric spatial position, our theory predicts that both size and shape receptive field heterogeneity are necessary to induce information gain, whereas size heterogeneity alone is insufficient. We thus turned to CA1 hippocampal activity to test our theoretical predictions - in particular, to measure shape heterogeneity, which has previously received little attention. To overcome limitations of traditional methods for estimating place cell tuning, we developed a fully probabilistic approach for measuring size and shape heterogeneity, in which tuning estimates were strategically weighted by explicitly measured uncertainty arising from biased or incomplete traversals of the environment. Our method furnished evidence that hippocampal receptive fields indeed exhibit strong degrees of size and shape heterogeneity, abiding by the normative predictions of our theory. Overall, our work makes novel predictions about the relative benefits of receptive field heterogeneities beyond our application to place cells, and provides a principled technique for testing them.Competing Interest StatementThe authors have declared no competing interest.National Institutes of Health, https://ror.org/01cwqze88, U19NS118246, R01NS116753Kempner Institute, Graduate fellowship
@article{Cohen2025, author = {Cohen, Zach and Drugowitsch, Jan}, title = {A unifying theory of receptive field heterogeneity predicts hippocampal spatial tuning}, elocation-id = {2025.07.26.666958}, year = {2025}, doi = {10.1101/2025.07.26.666958}, publisher = {Cold Spring Harbor Laboratory}, url = {https://www.biorxiv.org/content/early/2025/07/31/2025.07.26.666958}, journal = {bioRxiv}, } - NatNeuro
 Multimodal cue integration and learning in a neural representation of head directionMelanie A. Basnak, Anna Kutschireiter, Tatsuo S. Okubo, Albert Chen, Pavel Gorelik, Jan Drugowitsch, and Rachel I. WilsonNature Neuroscience, Oct 2025
Multimodal cue integration and learning in a neural representation of head directionMelanie A. Basnak, Anna Kutschireiter, Tatsuo S. Okubo, Albert Chen, Pavel Gorelik, Jan Drugowitsch, and Rachel I. WilsonNature Neuroscience, Oct 2025Navigation requires us to take account of multiple spatial cues with varying levels of informativeness and learn their spatial relationships. Here we investigate this process in the Drosophila head direction system, which functions as a ring attractor and a topographic map of head direction. Using population calcium imaging and multimodal virtual reality environments, we show that increasing cue informativeness improves encoding accuracy and produces a narrower and higher bump of activity. When cues conflict, the more informative cue exerts more weight. A familiar cue is weighted more heavily and used to guide the remapping of a less familiar cue. When a cue is less informative, it is remapped more readily in response to cue conflict. All these results can be explained by an attractor model with plastic sensory synapses. Our findings provide a mechanistic explanation for how the brain assembles spatial representations through inference and learning.
@article{Basnak2025, author = {Basnak, Melanie A. and Kutschireiter, Anna and Okubo, Tatsuo S. and Chen, Albert and Gorelik, Pavel and Drugowitsch, Jan and Wilson, Rachel I.}, title = {Multimodal cue integration and learning in a neural representation of head direction}, journal = {Nature Neuroscience}, issn = {1546-1726}, year = {2025}, volume = {28}, pages = {1729-1740}, url = {https://doi.org/10.1038/s41593-024-01823-z}, doi = {10.1038/s41593-024-01823-z}, } - Annurev-vision
 Hierarchical Vector Analysis of Visual Motion PerceptionSamuel J. Gershman, Johannes Bill, and Jan DrugowitschAnnual Review of Vision Science, Oct 2025
Hierarchical Vector Analysis of Visual Motion PerceptionSamuel J. Gershman, Johannes Bill, and Jan DrugowitschAnnual Review of Vision Science, Oct 2025Visual scenes are often populated by densely layered and complex patterns of motion. The problem of motion parsing is to break down these patterns into simpler components that are meaningful for perception and action. Psychophysical evidence suggests that the brain decomposes motion patterns into a hierarchy of relative motion vectors. Recent computational models have shed light on the algorithmic and neural basis of this parsing strategy. We review these models and the experiments that were designed to test their predictions. Zooming out, we argue that hierarchical motion perception is a tractable model system for understanding how aspects of high-level cognition such as compositionality may be implemented in neural circuitry.
@article{Gershman2025, author = {Gershman, Samuel J. and Bill, Johannes and Drugowitsch, Jan}, title = {Hierarchical Vector Analysis of Visual Motion Perception}, journal = {Annual Review of Vision Science}, issn = {2374-4642}, year = {2025}, publisher = {Annual Reviews}, url = {https://www.annualreviews.org/content/journals/10.1146/annurev-vision-110323-031344}, doi = {10.1146/annurev-vision-110323-031344}, pages = {411-422}, } - Nature
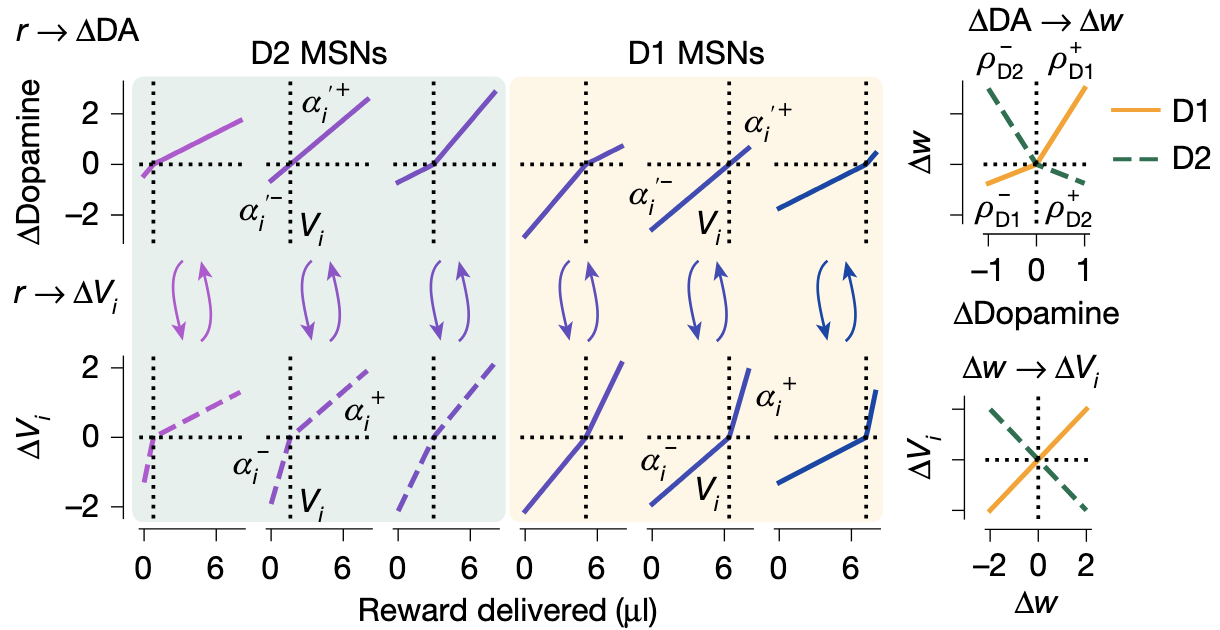 An opponent striatal circuit for distributional reinforcement learningAdam S. Lowet, Qiao Zheng, Melissa Meng, Sata Matias, Drugowitsch Jan, and Naoshige UchidaNature, Oct 2025
An opponent striatal circuit for distributional reinforcement learningAdam S. Lowet, Qiao Zheng, Melissa Meng, Sata Matias, Drugowitsch Jan, and Naoshige UchidaNature, Oct 2025Machine learning research has achieved large performance gains on a wide range of tasks by expanding the learning target from mean rewards to entire probability distributions of rewards—an approach known as distributional reinforcement learning (RL). The mesolimbic dopamine system is thought to underlie RL in the mammalian brain by updating a representation of mean value in the striatum2, but little is known about whether, where and how neurons in this circuit encode information about higher-order moments of reward distributions3. Here, to fill this gap, we used high-density probes (Neuropixels) to record striatal activity from mice performing a classical conditioning task in which reward mean, reward variance and stimulus identity were independently manipulated. In contrast to traditional RL accounts, we found robust evidence for abstract encoding of variance in the striatum. Chronic ablation of dopamine inputs disorganized these distributional representations in the striatum without interfering with mean value coding. Two-photon calcium imaging and optogenetics revealed that the two major classes of striatal medium spiny neurons—D1 and D2—contributed to this code by preferentially encoding the right and left tails of the reward distribution, respectively. We synthesize these findings into a new model of the striatum and mesolimbic dopamine that harnesses the opponency between D1 and D2 medium spiny neurons4–9 to reap the computational benefits of distributional RL.
@article{Lowet2025, title = {An opponent striatal circuit for distributional reinforcement learning}, journal = {Nature}, year = {2025}, volume = {639}, pages = {717-726}, doi = {10.1038/s41586-024-08488-5}, url = {https://doi.org/10.1038/s41586-024-08488-5}, author = {Lowet, Adam S. and Zheng, Qiao and Meng, Melissa and Matias, Sata and Jan, Drugowitsch and Uchida, Naoshige}, }






2024
- OSF
 Major sources of computational complexity in complex decision-makingJan Drugowitsch, and Alexandre PougetNov 2024
Major sources of computational complexity in complex decision-makingJan Drugowitsch, and Alexandre PougetNov 2024What makes decision-making hard, and what determines the time it takes to make a decision? For simple decisions, the standard answer implicates neuronal noise: its presence makes decisions hard, and averaging it out comes at the cost of long reaction times. We argue that this explanation is unlikely to hold for complex decisions. Instead, complex decisions are constrained by two main factors: memory retrieval and value computation. Indeed, most decisions require retrieving relevant information from memory, and use it to compute the choice options’ values. For the large memories of vertebrate brains, both operations can be extremely complex even if the neural circuits implementing them are perfectly noiseless. Yet, the importance of these factors has not yet been fully recognized in systems neuroscience, which tends to focus on tasks in which values are retrieved from simple noisy look-up tables. The interrogation of more complex and realistic tasks, similar to the ones used in human research, might help bridge this gap.
@misc{DrugowitschPouget2024, title = {Major sources of computational complexity in complex decision-making}, url = {osf.io/vw4yr}, doi = {10.31219/osf.io/vw4yr}, publisher = {OSF Preprints}, author = {Drugowitsch, Jan and Pouget, Alexandre}, year = {2024}, month = nov, } - CellReports
 Nerve injury disrupts temporal processing in the spinal cord dorsal horn through alterations in PV+ interneuronsGenelle Rankin, Anda M. Chirila, Alan J. Emanuel, Zihe Zhang, Clifford J. Woolf, Jan Drugowitsch, and David D. GintyCell Reports, Nov 2024
Nerve injury disrupts temporal processing in the spinal cord dorsal horn through alterations in PV+ interneuronsGenelle Rankin, Anda M. Chirila, Alan J. Emanuel, Zihe Zhang, Clifford J. Woolf, Jan Drugowitsch, and David D. GintyCell Reports, Nov 2024How mechanical allodynia following nerve injury is encoded in patterns of neural activity in the spinal cord dorsal horn (DH) remains incompletely understood. We address this in mice using the spared nerve injury model of neuropathic pain and in vivo electrophysiological recordings. Surprisingly, despite dramatic behavioral over-reactivity to mechanical stimuli following nerve injury, an overall increase in sensitivity or reactivity of DH neurons is not observed. We do, however, observe a marked decrease in correlated neural firing patterns, including the synchrony of mechanical stimulus-evoked firing, across the DH. Alterations in DH temporal firing patterns are recapitulated by silencing DH parvalbumin+ (PV+) interneurons, previously implicated in mechanical allodynia, as are allodynic pain-like behaviors. These findings reveal decorrelated DH network activity, driven by alterations in PV+ interneurons, as a prominent feature of neuropathic pain and suggest restoration of proper temporal activity as a potential therapeutic strategy to treat chronic neuropathic pain.
@article{Rankin2024, title = {Nerve injury disrupts temporal processing in the spinal cord dorsal horn through alterations in PV+ interneurons}, journal = {Cell Reports}, volume = {43}, number = {2}, pages = {113718}, year = {2024}, issn = {2211-1247}, doi = {10.1016/j.celrep.2024.113718}, url = {https://www.sciencedirect.com/science/article/pii/S2211124724000469}, author = {Rankin, Genelle and Chirila, Anda M. and Emanuel, Alan J. and Zhang, Zihe and Woolf, Clifford J. and Drugowitsch, Jan and Ginty, David D.}, keywords = {spinal cord dorsal horn, mechanical allodynia, dorsal horn inhibition, in vivo electrophysiology, dorsal horn network activity}, }


2023
- PhilTransRSocB
 Causal inference during closed-loop navigation: parsing of self- and object-motionJean-Paul Noel, Johanes Bill, Haoran Ding, John Vastola, Gregory C DeAngelis, Dora Angelaki, and Jan DrugowitschPhilosophical Transactions of the Royal Society B, Aug 2023
Causal inference during closed-loop navigation: parsing of self- and object-motionJean-Paul Noel, Johanes Bill, Haoran Ding, John Vastola, Gregory C DeAngelis, Dora Angelaki, and Jan DrugowitschPhilosophical Transactions of the Royal Society B, Aug 2023A key computation in building adaptive internal models of the external world is to ascribe sensory signals to their likely cause(s), a process of causal inference (CI). CI is well studied within the framework of two-alternative forced-choice tasks, but less well understood within the cadre of naturalistic action–perception loops. Here, we examine the process of disambiguating retinal motion caused by self- and/or object-motion during closed-loop navigation. First, we derive a normative account specifying how observers ought to intercept hidden and moving targets given their belief about (i) whether retinal motion was caused by the target moving, and (ii) if so, with what velocity. Next, in line with the modelling results, we show that humans report targets as stationary and steer towards their initial rather than final position more often when they are themselves moving, suggesting a putative misattribution of object-motion to the self. Further, we predict that observers should misattribute retinal motion more often: (i) during passive rather than active self-motion (given the lack of an efference copy informing self-motion estimates in the former), and (ii) when targets are presented eccentrically rather than centrally (given that lateral self-motion flow vectors are larger at eccentric locations during forward self-motion). Results support both of these predictions. Lastly, analysis of eye movements show that, while initial saccades toward targets were largely accurate regardless of the self-motion condition, subsequent gaze pursuit was modulated by target velocity during object-only motion, but not during concurrent object- and self-motion. These results demonstrate CI within action–perception loops, and suggest a protracted temporal unfolding of the computations characterizing CI.
@article{philtransrsocb2023, title = {Causal inference during closed-loop navigation: parsing of self- and object-motion}, author = {Noel, Jean-Paul and Bill, Johanes and Ding, Haoran and Vastola, John and DeAngelis, Gregory C and Angelaki, Dora and Drugowitsch, Jan}, journal = {Philosophical Transactions of the Royal Society B}, volume = {378}, issue = {1886}, pages = {20220344}, year = {2023}, month = aug, doi = {10.1098/rstb.2022.0344}, url = {https://doi.org/10.1098/rstb.2022.0344}, } - CerebCortex
 Diverse effects of gaze direction on heading perception in humansWei Gao, Yipeng Lin, Jiangrong Shen, Jianing Han, Xiaoxiao Song, Yukun Lu, Huijia Zhan, Qianbing Li, and 6 more authorsCerebral Cortex, Feb 2023
Diverse effects of gaze direction on heading perception in humansWei Gao, Yipeng Lin, Jiangrong Shen, Jianing Han, Xiaoxiao Song, Yukun Lu, Huijia Zhan, Qianbing Li, and 6 more authorsCerebral Cortex, Feb 2023Gaze change can misalign spatial reference frames encoding visual and vestibular signals in cortex, which may affect the heading discrimination. Here, by systematically manipulating the eye-in-head and head-on-body positions to change the gaze direction of subjects, the performance of heading discrimination was tested with visual, vestibular, and combined stimuli in a reaction-time task in which the reaction time is under the control of subjects. We found the gaze change induced substantial biases in perceived heading, increased the threshold of discrimination and reaction time of subjects in all stimulus conditions. For the visual stimulus, the gaze effects were induced by changing the eye-in-world position, and the perceived heading was biased in the opposite direction of gaze. In contrast, the vestibular gaze effects were induced by changing the eye-in-head position, and the perceived heading was biased in the same direction of gaze. Although the bias was reduced when the visual and vestibular stimuli were combined, integration of the 2 signals substantially deviated from predictions of an extended diffusion model that accumulates evidence optimally over time and across sensory modalities. These findings reveal diverse gaze effects on the heading discrimination and emphasize that the transformation of spatial reference frames may underlie the effects.
@article{cerebcortex2023, author = {Gao, Wei and Lin, Yipeng and Shen, Jiangrong and Han, Jianing and Song, Xiaoxiao and Lu, Yukun and Zhan, Huijia and Li, Qianbing and Ge, Haoting and Lin, Zheng and Shi, Wenlei and Drugowitsch, Jan and Tang, Huajin and Chen, Xiaodong}, title = {{Diverse effects of gaze direction on heading perception in humans}}, journal = {Cerebral Cortex}, volume = {33}, number = {11}, pages = {6772-6784}, year = {2023}, month = feb, issn = {1047-3211}, doi = {10.1093/cercor/bhac541}, url = {https://doi.org/10.1093/cercor/bhac541}, } - PNAS
 Bayesian inference in ring attractor networksAnna Kutschireiter, Melanie A Basnak, Rachel I. Wilson, and Jan DrugowitschProceedings of the National Academy of Sciences, Feb 2023
Bayesian inference in ring attractor networksAnna Kutschireiter, Melanie A Basnak, Rachel I. Wilson, and Jan DrugowitschProceedings of the National Academy of Sciences, Feb 2023Working memories are thought to be held in attractor networks in the brain. These attractors should keep track of the uncertainty associated with each memory, so as to weigh it properly against conflicting new evidence. However, conventional attractors do not represent uncertainty. Here, we show how uncertainty could be incorporated into an attractor, specifically a ring attractor that encodes head direction. First, we introduce a rigorous normative framework (the circular Kalman filter) for benchmarking the performance of a ring attractor under conditions of uncertainty. Next, we show that the recurrent connections within a conventional ring attractor can be retuned to match this benchmark. This allows the amplitude of network activity to grow in response to confirmatory evidence, while shrinking in response to poor-quality or strongly conflicting evidence. This “Bayesian ring attractor” performs near-optimal angular path integration and evidence accumulation. Indeed, we show that a Bayesian ring attractor is consistently more accurate than a conventional ring attractor. Moreover, near-optimal performance can be achieved without exact tuning of the network connections. Finally, we use large-scale connectome data to show that the network can achieve near-optimal performance even after we incorporate biological constraints. Our work demonstrates how attractors can implement a dynamic Bayesian inference algorithm in a biologically plausible manner, and it makes testable predictions with direct relevance to the head direction system as well as any neural system that tracks direction, orientation, or periodic rhythms.
@article{pnas2023, title = {Bayesian inference in ring attractor networks}, author = {Kutschireiter, Anna and Basnak, Melanie A and Wilson, Rachel I. and Drugowitsch, Jan}, journal = {Proceedings of the National Academy of Sciences}, volume = {120}, issue = {9}, pages = {e2210622120}, year = {2023}, month = feb, doi = {10.1073/pnas.2210622120}, url = {https://doi.org/10.1073/pnas.2210622120}, } - PMLR
 Is the information geometry of probabilistic population codes learnable?John J. Vastola, Zach Cohen, and Jan DrugowitschIn Proceedings of the 1st NeurIPS Workshop on Symmetry and Geometry in Neural Representations, 03 dec 2023
Is the information geometry of probabilistic population codes learnable?John J. Vastola, Zach Cohen, and Jan DrugowitschIn Proceedings of the 1st NeurIPS Workshop on Symmetry and Geometry in Neural Representations, 03 dec 2023One reason learning the geometry of latent neural manifolds from neural activity data is difficult is that the ground truth is generally not known, which can make manifold learning methods hard to evaluate. Probabilistic population codes (PPCs), a class of biologically plausible and self-consistent models of neural populations that encode parametric probability distributions, may offer a theoretical setting where it is possible to rigorously study manifold learning. It is natural to define the neural manifold of a PPC as the statistical manifold of the encoded distribution, and we derive a mathematical result that the information geometry of the statistical manifold is directly related to measurable covariance matrices. This suggests a simple but rigorously justified decoding strategy based on principal component analysis, which we illustrate using an analytically tractable PPC.




2022
- NatHumBeh
 Efficient stabilization of imprecise statistical inference through conditional belief updatingJulie Drevet, Jan Drugowitsch, and Valentin WyartNature Human Behaviour, Dec 2022
Efficient stabilization of imprecise statistical inference through conditional belief updatingJulie Drevet, Jan Drugowitsch, and Valentin WyartNature Human Behaviour, Dec 2022Statistical inference is the optimal process for forming and maintaining accurate beliefs about uncertain environments. However, human inference comes with costs due to its associated biases and limited precision. Indeed, biased or imprecise inference can trigger variable beliefs and unwarranted changes in behaviour. Here, by studying decisions in a sequential categorization task based on noisy visual stimuli, we obtained converging evidence that humans reduce the variability of their beliefs by updating them only when the reliability of incoming sensory information is judged as sufficiently strong. Instead of integrating the evidence provided by all stimuli, participants actively discarded as much as a third of stimuli. This conditional belief updating strategy shows good test–retest reliability, correlates with perceptual confidence and explains human behaviour better than previously described strategies. This seemingly suboptimal strategy not only reduces the costs of imprecise computations but also, counterintuitively, increases the accuracy of resulting decisions.
@article{nathumanbehav2022, title = {Efficient stabilization of imprecise statistical inference through conditional belief updating}, author = {Drevet, Julie and Drugowitsch, Jan and Wyart, Valentin}, journal = {Nature Human Behaviour}, volume = {6}, pages = {1691--1704}, year = {2022}, month = dec, doi = {10.1038/s41562-022-01445-0}, url = {https://doi.org/10.1038/s41562-022-01445-0}, data = {https://figshare.com/projects/Efficient_stabilization_of_imprecise_statistical_inference_through_conditional_belief_updating/140170}, } - NatComms
 Visual motion perception as online hierarchical inferenceJohannes Bill, Samuel J. Gershman, and Jan DrugowitschNature Communications, Dec 2022
Visual motion perception as online hierarchical inferenceJohannes Bill, Samuel J. Gershman, and Jan DrugowitschNature Communications, Dec 2022Identifying the structure of motion relations in the environment is critical for navigation, tracking, prediction, and pursuit. Yet, little is known about the mental and neural computations that allow the visual system to infer this structure online from a volatile stream of visual information. We propose online hierarchical Bayesian inference as a principled solution for how the brain might solve this complex perceptual task. We derive an online Expectation-Maximization algorithm that explains human percepts qualitatively and quantitatively for a diverse set of stimuli, covering classical psychophysics experiments, ambiguous motion scenes, and illusory motion displays. We thereby identify normative explanations for the origin of human motion structure perception and make testable predictions for future psychophysics experiments. The proposed online hierarchical inference model furthermore affords a neural network implementation which shares properties with motion-sensitive cortical areas and motivates targeted experiments to reveal the neural representations of latent structure.
@article{natcomms2022, title = {Visual motion perception as online hierarchical inference}, author = {Bill, Johannes and Gershman, Samuel J. and Drugowitsch, Jan}, journal = {Nature Communications}, volume = {13}, issue = {1}, pages = {1--17}, year = {2022}, month = dec, doi = {10.1038/s41467-022-34805-5}, url = {https://doi.org/10.1038/s41467-022-34805-5}, } - JOSE
 Neuromatch Academy: a 3-week, online summer school in computational neuroscienceBernard ’t Hart, Titipat Achakulvisut, Ayoade Adeyemi, Athena Akrami, Bradly Alicea, Alicia Alonso-Andres, Diego Alzate-Correa, Arash Ash, and 154 more authorsJournal of Open Source Education, Dec 2022
Neuromatch Academy: a 3-week, online summer school in computational neuroscienceBernard ’t Hart, Titipat Achakulvisut, Ayoade Adeyemi, Athena Akrami, Bradly Alicea, Alicia Alonso-Andres, Diego Alzate-Correa, Arash Ash, and 154 more authorsJournal of Open Source Education, Dec 2022@article{jose2022, doi = {10.21105/jose.00118}, url = {https://doi.org/10.21105/jose.00118}, year = {2022}, publisher = {The Open Journal}, volume = {5}, number = {49}, pages = {118}, author = {{'t Hart}, Bernard and Achakulvisut, Titipat and Adeyemi, Ayoade and Akrami, Athena and Alicea, Bradly and Alonso-Andres, Alicia and Alzate-Correa, Diego and Ash, Arash and Ballesteros, Jesus and Balwani, Aishwarya and Batty, Eleanor and Beierholm, Ulrik and Benjamin, Ari and Bhalla, Upinder and Blohm, Gunnar and Blohm, Joachim and Bonnen, Kathryn and Brigham, Marco and Brunton, Bingni and Butler, John and Caie, Brandon and Gajic, N and Chatterjee, Sharbatanu and Chavlis, Spyridon and Chen, Ruidong and Cheng, You and Chow, H.m. and Chua, Raymond and Dai, Yunwei and David, Isaac and DeWitt, Eric and Denis, Julien and Dipani, Alish and Dorschel, Arianna and Drugowitsch, Jan and Dwivedi, Kshitij and Escola, Sean and Fan, Haoxue and Farhoodi, Roozbeh and Fei, Yicheng and Fiquet, Pierre-Étienne and Fontolan, Lorenzo and Forest, Jeremy and Fujishima, Yuki and Galbraith, Byron and Galdamez, Mario and Gao, Richard and Gjorgjieva, Julijana and Gonzalez, Alexander and Gu, Qinglong and Guo, Yueqi and Guo, Ziyi and Gupta, Pankaj and Gurbuz, Busra and Haimerl, Caroline and Harrod, Jordan and Hyafil, Alexandre and Irani, Martin and Jacobson, Daniel and Johnson, Michelle and Jones, Ilenna and Karni, Gili and Kass, Robert and Kim, Hyosub and Kist, Andreas and Koene, Randal and Kording, Konrad and Krause, Matthew and Kumar, Arvind and Kühn, Norma and Lc, Ray and Laporte, Matthew and Lee, Junseok and Li, Songting and Lin, Sikun and Lin, Yang and Liu, Shuze and Liu, Tony and Livezey, Jesse and Lu, Linlin and Macke, Jakob and Mahaffy, Kelly and Martins, A and Martorell, Nicolás and Martínez, Manolo and Mattar, Marcelo and Menendez, Jorge and Miller, Kenneth and Mineault, Patrick and Mohammadi, Nosratullah and Mohsenzadeh, Yalda and Morgenroth, Elenor and Morshedzadeh, Taha and Mosberger, Alice and Muliya, Madhuvanthi and Mur, Marieke and Murray, John and Nd, Yashas and Naud, Richard and Nayak, Prakriti and Oak, Anushka and Castillo, Itzel and Orouji, Seyedmehdi and Otero-Millan, Jorge and Pachitariu, Marius and Pandey, Biraj and Paredes, Renato and Parent, Jesse and Park, Il and Peters, Megan and Pitkow, Xaq and Poirazi, Panayiota and Popal, Haroon and Prabhakaran, Sandhya and Qiu, Tian and Ragunathan, Srinidhi and Rodriguez-Cruces, Raul and Rolnick, David and Sahoo, Ashish and Salehinajafabadi, Saeed and Savin, Cristina and Saxena, Shreya and Schrater, Paul and Schroeder, Karen and Schwarze, Alice and Sedigh-Sarvestani, Madineh and Sekhar, K and Shadmehr, Reza and Shanechi, Maryam and Sharma, Siddhant and Shea-Brown, Eric and Shenoy, Krishna and Shimabukuro, Carolina and Shuvaev, Sergey and Sin, Man and Smith, Maurice and Steinmetz, Nicholas and Stosio, Karolina and Straley, Elizabeth and Strandquist, Gabrielle and Stringer, Carsen and Tomar, Rimjhim and Tran, Ngoc and Triantafillou, Sofia and Udeigwe, Lawrence and Valeriani, Davide and Valton, Vincent and Vaziri-Pashkam, Maryam and Vincent, Peter and Vishne, Gal and Wallisch, Pascal and Wang, Peiyuan and Ward, Claire and Waskom, Michael and Wei, Kunlin and Wu, Anqi and Wu, Zhengwei and Wyble, Brad and Zhang, Lei and Zysman, Daniel and Uquillas, Federico and van Viegen, Tara}, title = {Neuromatch Academy: a 3-week, online summer school in computational neuroscience}, journal = {Journal of Open Source Education}, } - eLife
 Controllability boosts neural and cognitive signatures of changes-of-mind in uncertain environmentsMarion Rouault, Aurélien Weiss, Junseok K Lee, Jan Drugowitsch, Valerian Chambon, and Valentin WyarteLife, Sep 2022
Controllability boosts neural and cognitive signatures of changes-of-mind in uncertain environmentsMarion Rouault, Aurélien Weiss, Junseok K Lee, Jan Drugowitsch, Valerian Chambon, and Valentin WyarteLife, Sep 2022In uncertain environments, seeking information about alternative choice options is essential for adaptive learning and decision-making. However, information seeking is usually confounded with changes-of-mind about the reliability of the preferred option. Here, we exploited the fact that information seeking requires control over which option to sample to isolate its behavioral and neurophysiological signatures. We found that changes-of-mind occurring with control require more evidence against the current option, are associated with reduced confidence, but are nevertheless more likely to be confirmed on the next decision. Multimodal neurophysiological recordings showed that these changes-of-mind are preceded by stronger activation of the dorsal attention network in magnetoencephalography, and followed by increased pupil-linked arousal during the presentation of decision outcomes. Together, these findings indicate that information seeking increases the saliency of evidence perceived as the direct consequence of one’s own actions.
@article{elife2022, article_type = {journal}, title = {Controllability boosts neural and cognitive signatures of changes-of-mind in uncertain environments}, author = {Rouault, Marion and Weiss, Aurélien and Lee, Junseok K and Drugowitsch, Jan and Chambon, Valerian and Wyart, Valentin}, editor = {Roiser, Jonathan and Frank, Michael J and Press, Clare}, volume = {11}, year = {2022}, month = sep, pub_date = {2022-09-13}, pages = {e75038}, citation = {eLife 2022;11:e75038}, doi = {10.7554/eLife.75038}, url = {https://doi.org/10.7554/eLife.75038}, keywords = {confidence, information seeking, exploration, inference, decision-making}, journal = {eLife}, issn = {2050-084X}, publisher = {eLife Sciences Publications, Ltd}, } - RLDM
 Hierarchical structure learning for perceptual decision making in visual motion perceptionJohannes Bill, Samuel J. Gershman, and Jan DrugowitschIn The 5th Multi-disciplinary Conference on Reinforcement Learning and Decision Making (RLDM-22). Brown University, Providence, RI, USA., May 2022
Hierarchical structure learning for perceptual decision making in visual motion perceptionJohannes Bill, Samuel J. Gershman, and Jan DrugowitschIn The 5th Multi-disciplinary Conference on Reinforcement Learning and Decision Making (RLDM-22). Brown University, Providence, RI, USA., May 2022Successful behavior in the real world critically depends on discovering the latent structure behind the volatile inputs reaching our sensory system. Our brains face the online task of discovering structure at multiple timescales ranging from short-lived correlations, to the structure underlying a scene, to life-time learning of causal relations. Little is known about the mental and neural computations driving the brain’s ability of online, multi-timescale structure inference. We studied these computations by the example of visual motion perception owing to the importance of structured motion for behavior. We propose online hierarchical Bayesian inference as a principled solution for how the brain might solve multi-timescale structure inference. We derive an online Expectation-Maximization algorithm that continually updates an estimate of a visual scene’s underlying structure while using this inferred structure to organize incoming noisy velocity observations into meaningful, stable percepts. We show that the algorithm explains human percepts qualitatively and quantitatively for a diverse set of stimuli, covering classical psychophysics experiments, ambiguous motion scenes, and illusory motion displays. It explains experimental results of human motion structure classification with higher fidelity than a previous ideal observer-based model, and provides normative explanations for the origin of biased perception in motion direction repulsion experiments. To identify a scene’s structure the algorithm recruits motion components from a set of frequently occurring features, such as global translation or grouping of stimuli. We demonstrate in computer simulations how these features can be learned online from experience. Finally, the algorithm affords a neural network implementation which shares properties with motion-sensitive cortical areas MT and MSTd and motivates a novel class of neuroscientific experiments to reveal the neural representations of latent structure.
@inproceedings{rldm2022, title = {Hierarchical structure learning for perceptual decision making in visual motion perception}, author = {Bill, Johannes and Gershman, Samuel J. and Drugowitsch, Jan}, booktitle = {The 5th Multi-disciplinary Conference on Reinforcement Learning and Decision Making (RLDM-22). Brown University, Providence, RI, USA.}, year = {2022}, month = may, page = {1--4}, } - Neuron
 A large majority of awake hippocampal sharp-wave ripples feature spatial trajectories with momentumEmma L. Krause, and Jan DrugowitschNeuron, May 2022
A large majority of awake hippocampal sharp-wave ripples feature spatial trajectories with momentumEmma L. Krause, and Jan DrugowitschNeuron, May 2022During periods of rest, hippocampal place cells feature bursts of activity called sharp-wave ripples (SWRs). Heuristic approaches have revealed that a small fraction of SWRs appear to “simulate” trajectories through the environment, called awake hippocampal replay. However, the functional role of a majority of these SWRs remains unclear. We find, using Bayesian model comparison of state-space models to characterize the spatiotemporal dynamics embedded in SWRs, that almost all SWRs of foraging rodents simulate such trajectories. Furthermore, these trajectories feature momentum, or inertia in their velocities, that mirrors the animals’ natural movement, in contrast to replay events during sleep, which lack such momentum. Last, we show that past analyses of replayed trajectories for navigational planning were biased by the heuristic SWR sub-selection. Our findings thus identify the dominant function of awake SWRs as simulating trajectories with momentum and provide a principled foundation for future work on their computational function.
@article{neuron2022, title = {A large majority of awake hippocampal sharp-wave ripples feature spatial trajectories with momentum}, journal = {Neuron}, volume = {110}, number = {4}, pages = {722-733.e8}, year = {2022}, issn = {0896-6273}, doi = {10.1016/j.neuron.2021.11.014}, url = {https://www.sciencedirect.com/science/article/pii/S0896627321009521}, author = {Krause, Emma L. and Drugowitsch, Jan}, keywords = {sharp-wave ripples, hippocampal replay, hippocampus, state-space models, Bayesian model comparison}, } - IEEETSP
 Projection Filtering With Observed State Increments With Applications in Continuous-Time Circular FilteringAnna Kutschireiter, Luke Rast, and Jan DrugowitschIEEE Transactions on Signal Processing, Jan 2022
Projection Filtering With Observed State Increments With Applications in Continuous-Time Circular FilteringAnna Kutschireiter, Luke Rast, and Jan DrugowitschIEEE Transactions on Signal Processing, Jan 2022Angular path integration is the ability of a system to estimate its own heading direction from potentially noisy angular velocity (or increment) observations. Non-probabilistic algorithms for angular path integration, which rely on a summation of these noisy increments, do not appropriately take into account the reliability of such observations, which is essential for appropriately weighing one’s current heading direction estimate against incoming information. In a probabilistic setting, angular path integration can be formulated as a continuous-time nonlinear filtering problem (circular filtering) with observed state increments. The circular symmetry of heading direction makes this inference task inherently nonlinear, thereby precluding the use of popular inference algorithms such as Kalman filters, rendering the problem analytically inaccessible. Here, we derive an approximate solution to circular continuous-time filtering, which integrates state increment observations while maintaining a fixed representation through both state propagation and observational updates. Specifically, we extend the established projection-filtering method to account for observed state increments and apply this framework to the circular filtering problem. We further propose a generative model for continuous-time angular-valued direct observations of the hidden state, which we integrate seamlessly into the projection filter. Applying the resulting scheme to a model of probabilistic angular path integration, we derive an algorithm for circular filtering, which we term the circular Kalman filter. Importantly, this algorithm is analytically accessible, interpretable, and outperforms an alternative filter based on a Gaussian approximation.
@article{ieeetsp2022, author = {Kutschireiter, Anna and Rast, Luke and Drugowitsch, Jan}, journal = {IEEE Transactions on Signal Processing}, title = {Projection Filtering With Observed State Increments With Applications in Continuous-Time Circular Filtering}, year = {2022}, volume = {70}, number = {}, pages = {686-700}, doi = {10.1109/TSP.2022.3143471}, month = jan, url = {https://doi.org/10.1109/TSP.2022.3143471}, }






2021
- NatComms
 Interacting with volatile environments stabilizes hidden-state inference and its brain signaturesAurélien Weiss, Valérian Chambon, Junseok K. Lee, Jan Drugowitsch, and Valentin WyartNature Communications, Jan 2021
Interacting with volatile environments stabilizes hidden-state inference and its brain signaturesAurélien Weiss, Valérian Chambon, Junseok K. Lee, Jan Drugowitsch, and Valentin WyartNature Communications, Jan 2021Making accurate decisions in uncertain environments requires identifying the generative cause of sensory cues, but also the expected outcomes of possible actions. Although both cognitive processes can be formalized as Bayesian inference, they are commonly studied using different experimental frameworks, making their formal comparison difficult. Here, by framing a reversal learning task either as cue-based or outcome-based inference, we found that humans perceive the same volatile environment as more stable when inferring its hidden state by interaction with uncertain outcomes than by observation of equally uncertain cues. Multivariate patterns of magnetoencephalographic (MEG) activity reflected this behavioral difference in the neural interaction between inferred beliefs and incoming evidence, an effect originating from associative regions in the temporal lobe. Together, these findings indicate that the degree of control over the sampling of volatile environments shapes human learning and decision-making under uncertainty.
@article{natcomms2021b, title = {Interacting with volatile environments stabilizes hidden-state inference and its brain signatures}, journal = {Nature Communications}, volume = {12}, number = {2228}, pages = {1--17}, year = {2021}, doi = {10.1038/s41467-021-22396-6}, url = {https://doi.org/10.1038/s41467-021-22396-6}, author = {Weiss, Aurélien and Chambon, Valérian and Lee, Junseok K. and Drugowitsch, Jan and Wyart, Valentin}, } - eLife
 Optimal policy for attention-modulated decisions explains human fixation behaviorAnthony I. Jang, Ravi Sharma, and Jan DrugowitscheLife, Mar 2021
Optimal policy for attention-modulated decisions explains human fixation behaviorAnthony I. Jang, Ravi Sharma, and Jan DrugowitscheLife, Mar 2021Traditional accumulation-to-bound decision-making models assume that all choice options are processed with equal attention. In real life decisions, however, humans alternate their visual fixation between individual items to efficiently gather relevant information (Yang et al., 2016). These fixations also causally affect one’s choices, biasing them toward the longer-fixated item (Krajbich et al., 2010). We derive a normative decision-making model in which attention enhances the reliability of information, consistent with neurophysiological findings (Cohen and Maunsell, 2009). Furthermore, our model actively controls fixation changes to optimize information gathering. We show that the optimal model reproduces fixation-related choice biases seen in humans and provides a Bayesian computational rationale for this phenomenon. This insight led to additional predictions that we could confirm in human data. Finally, by varying the relative cognitive advantage conferred by attention, we show that decision performance is benefited by a balanced spread of resources between the attended and unattended items.
@article{elife2021, article_type = {journal}, title = {Optimal policy for attention-modulated decisions explains human fixation behavior}, author = {Jang, Anthony I. and Sharma, Ravi and Drugowitsch, Jan}, editor = {Tsetsos, Konstantinos and Gold, Joshua I and Tsetsos, Konstantinos}, volume = {10}, year = {2021}, month = mar, pub_date = {2021-03-26}, pages = {e63436}, citation = {eLife 2021;10:e63436}, doi = {10.7554/eLife.63436}, url = {https://doi.org/10.7554/eLife.63436}, keywords = {decision-making, visual attention, diffusion models, optimality}, journal = {eLife}, issn = {2050-084X}, publisher = {eLife Sciences Publications, Ltd}, data = {https://doi.org/10.5281/zenodo.4636831}, } - SciRep
 Human visual motion perception shows hallmarks of Bayesian structural inferenceSichao Yang, Johannes Bill, Drugowitsch Jan, and Samuel J. GershmanScientific Reports, Feb 2021
Human visual motion perception shows hallmarks of Bayesian structural inferenceSichao Yang, Johannes Bill, Drugowitsch Jan, and Samuel J. GershmanScientific Reports, Feb 2021Motion relations in visual scenes carry an abundance of behaviorally relevant information, but little is known about how humans identify the structure underlying a scene’s motion in the first place. We studied the computations governing human motion structure identification in two psychophysics experiments and found that perception of motion relations showed hallmarks of Bayesian structural inference. At the heart of our research lies a tractable task design that enabled us to reveal the signatures of probabilistic reasoning about latent structure. We found that a choice model based on the task’s Bayesian ideal observer accurately matched many facets of human structural inference, including task performance, perceptual error patterns, single-trial responses, participant-specific differences, and subjective decision confidence—especially, when motion scenes were ambiguous and when object motion was hierarchically nested within other moving reference frames. Our work can guide future neuroscience experiments to reveal the neural mechanisms underlying higher-level visual motion perception.
@article{scirep2021, title = {Human visual motion perception shows hallmarks of Bayesian structural inference}, author = {Yang, Sichao and Bill, Johannes and Jan, Drugowitsch and Gershman, Samuel J.}, volume = {11}, issue = {3714}, year = {2021}, month = feb, pages = {1-14}, doi = {10.1038/s41598-021-82175-7}, url = {https://doi.org/10.1038/s41598-021-82175-7}, journal = {Scientific Reports}, data = {https://github.com/DrugowitschLab/motion-structure-identification}, } - NatComms
 Scaling of sensory information in large neural populations shows signatures of information-limiting correlationsMohammadMehdi Kafashan, Anna W. Jaffe, Selmaan N. Chettih, Ramon Nogueira, Iñigo Arandia-Romero, Christopher D. Harvey, Rubén Moreno-Bote, and Jan DrugowitschNature Communications, Jan 2021
Scaling of sensory information in large neural populations shows signatures of information-limiting correlationsMohammadMehdi Kafashan, Anna W. Jaffe, Selmaan N. Chettih, Ramon Nogueira, Iñigo Arandia-Romero, Christopher D. Harvey, Rubén Moreno-Bote, and Jan DrugowitschNature Communications, Jan 2021How is information distributed across large neuronal populations within a given brain area? Information may be distributed roughly evenly across neuronal populations, so that total information scales linearly with the number of recorded neurons. Alternatively, the neural code might be highly redundant, meaning that total information saturates. Here we investigate how sensory information about the direction of a moving visual stimulus is distributed across hundreds of simultaneously recorded neurons in mouse primary visual cortex. We show that information scales sublinearly due to correlated noise in these populations. We compartmentalized noise correlations into information-limiting and nonlimiting components, then extrapolate to predict how information grows with even larger neural populations. We predict that tens of thousands of neurons encode 95% of the information about visual stimulus direction, much less than the number of neurons in primary visual cortex. These findings suggest that the brain uses a widely distributed, but nonetheless redundant code that supports recovering most sensory information from smaller subpopulations.
@article{natcomms2021a, title = {Scaling of sensory information in large neural populations shows signatures of information-limiting correlations}, author = {Kafashan, MohammadMehdi and Jaffe, Anna W. and Chettih, Selmaan N. and Nogueira, Ramon and Arandia-Romero, Iñigo and Harvey, Christopher D. and Moreno-Bote, Rubén and Drugowitsch, Jan}, volume = {12}, issue = {473}, year = {2021}, month = jan, pages = {1-16}, doi = {10.1038/s41467-020-20722-y}, url = {https://doi.org/10.1038/s41467-020-20722-y}, journal = {Nature Communications}, data = {https://doi.org/10.6084/m9.figshare.13274951}, }




2020
- TINS
 Distributional Reinforcement Learning in the BrainAdam S. Lowet, Qiao Zheng, Sara Matias, Jan Drugowitsch, and Naoshige UchidaTrends in Neurosciences, Oct 2020
Distributional Reinforcement Learning in the BrainAdam S. Lowet, Qiao Zheng, Sara Matias, Jan Drugowitsch, and Naoshige UchidaTrends in Neurosciences, Oct 2020Learning about rewards and punishments is critical for survival. Classical studies have demonstrated an impressive correspondence between the firing of dopamine neurons in the mammalian midbrain and the reward prediction errors of reinforcement learning algorithms, which express the difference between actual reward and predicted mean reward. However, it may be advantageous to learn not only the mean but also the complete distribution of potential rewards. Recent advances in machine learning have revealed a biologically plausible set of algorithms for reconstructing this reward distribution from experience. Here, we review the mathematical foundations of these algorithms as well as initial evidence for their neurobiological implementation. We conclude by highlighting outstanding questions regarding the circuit computation and behavioral readout of these distributional codes.
@article{tins2020, title = {Distributional Reinforcement Learning in the Brain}, journal = {Trends in Neurosciences}, volume = {43}, number = {12}, pages = {980-997}, year = {2020}, month = oct, issn = {0166-2236}, doi = {https://doi.org/10.1016/j.tins.2020.09.004}, url = {https://www.sciencedirect.com/science/article/pii/S0166223620301983}, author = {Lowet, Adam S. and Zheng, Qiao and Matias, Sara and Drugowitsch, Jan and Uchida, Naoshige}, keywords = {dopamine, population coding, reward, deep neural networks, machine learning, artificial intelligence}, } - PNAS
 Hierarchical structure is employed by humans during visual motion perceptionJohannes Bill, Hrag Pailian, Samuel J. Gershman, and Jan DrugowitschProceedings of the National Academy of Sciences, Sep 2020
Hierarchical structure is employed by humans during visual motion perceptionJohannes Bill, Hrag Pailian, Samuel J. Gershman, and Jan DrugowitschProceedings of the National Academy of Sciences, Sep 2020In the real world, complex dynamic scenes often arise from the composition of simpler parts. The visual system exploits this structure by hierarchically decomposing dynamic scenes: When we see a person walking on a train or an animal running in a herd, we recognize the individual’s movement as nested within a reference frame that is, itself, moving. Despite its ubiquity, surprisingly little is understood about the computations underlying hierarchical motion perception. To address this gap, we developed a class of stimuli that grant tight control over statistical relations among object velocities in dynamic scenes. We first demonstrate that structured motion stimuli benefit human multiple object tracking performance. Computational analysis revealed that the performance gain is best explained by human participants making use of motion relations during tracking. A second experiment, using a motion prediction task, reinforced this conclusion and provided fine-grained information about how the visual system flexibly exploits motion structure.
@article{pnas2020b, author = {Bill, Johannes and Pailian, Hrag and Gershman, Samuel J. and Drugowitsch, Jan}, title = {Hierarchical structure is employed by humans during visual motion perception}, journal = {Proceedings of the National Academy of Sciences}, volume = {117}, number = {39}, pages = {24581-24589}, year = {2020}, month = sep, doi = {10.1073/pnas.2008961117}, url = {https://www.pnas.org/doi/abs/10.1073/pnas.2008961117}, data = {https://doi.org/10.6084/m9.figshare.9856271.v1}, } - PNAS
 Heuristics and optimal solutions to the breadth–depth dilemmaRubén Moreno-Bote, Jorge Ramírez-Ruiz, Jan Drugowitsch, and Benjamin Y. HaydenProceedings of the National Academy of Sciences, Aug 2020
Heuristics and optimal solutions to the breadth–depth dilemmaRubén Moreno-Bote, Jorge Ramírez-Ruiz, Jan Drugowitsch, and Benjamin Y. HaydenProceedings of the National Academy of Sciences, Aug 2020In multialternative risky choice, we are often faced with the opportunity to allocate our limited information-gathering capacity between several options before receiving feedback. In such cases, we face a natural trade-off between breadth—spreading our capacity across many options—and depth—gaining more information about a smaller number of options. Despite its broad relevance to daily life, including in many naturalistic foraging situations, the optimal strategy in the breadth–depth trade-off has not been delineated. Here, we formalize the breadth–depth dilemma through a finite-sample capacity model. We find that, if capacity is small (∼10 samples), it is optimal to draw one sample per alternative, favoring breadth. However, for larger capacities, a sharp transition is observed, and it becomes best to deeply sample a very small fraction of alternatives, which roughly decreases with the square root of capacity. Thus, ignoring most options, even when capacity is large enough to shallowly sample all of them, is a signature of optimal behavior. Our results also provide a rich casuistic for metareasoning in multialternative decisions with bounded capacity using close-to-optimal heuristics.
@article{pnas2020a, author = {Moreno-Bote, Rubén and Ramírez-Ruiz, Jorge and Drugowitsch, Jan and Hayden, Benjamin Y.}, title = {Heuristics and optimal solutions to the breadth–depth dilemma}, journal = {Proceedings of the National Academy of Sciences}, volume = {117}, number = {33}, pages = {19799-19808}, year = {2020}, month = aug, doi = {10.1073/pnas.2004929117}, url = {https://www.pnas.org/doi/abs/10.1073/pnas.2004929117}, } - Science
 Meissner corpuscles and their spatially intermingled afferents underlie gentle touch perceptionNicole L. Neubarth, Alan J. Emanuel, Yin Liu, Mark W. Springel, Annie Handler, Qiyu Zhang, Brendan P. Lehnert, Chong Guo, and 11 more authorsScience, Jun 2020
Meissner corpuscles and their spatially intermingled afferents underlie gentle touch perceptionNicole L. Neubarth, Alan J. Emanuel, Yin Liu, Mark W. Springel, Annie Handler, Qiyu Zhang, Brendan P. Lehnert, Chong Guo, and 11 more authorsScience, Jun 2020The Meissner corpuscle, a mechanosensory end organ, was discovered more than 165 years ago and has since been found in the glabrous skin of all mammals, including that on human fingertips. Although prominently featured in textbooks, the function of the Meissner corpuscle is unknown. Neubarth et al. generated adult mice without Meissner corpuscles and used them to show that these corpuscles alone mediate behavioral responses to, and perception of, gentle forces (see the Perspective by Marshall and Patapoutian). Each Meissner corpuscle is innervated by two molecularly distinct, yet physiologically similar, mechanosensory neurons. These two neuronal subtypes are developmentally interdependent and their endings are intertwined within the corpuscle. Both Meissner mechanosensory neuron subtypes are homotypically tiled, ensuring uniform and complete coverage of the skin, yet their receptive fields are overlapping and offset with respect to each other. Science, this issue p. eabb2751; see also p. 1311 Light touch perception and fine sensorimotor control arise from spatially overlapping mechanoreceptors of the Meissner corpuscle. Meissner corpuscles are mechanosensory end organs that densely occupy mammalian glabrous skin. We generated mice that selectively lacked Meissner corpuscles and found them to be deficient in both perceiving the gentlest detectable forces acting on glabrous skin and fine sensorimotor control. We found that Meissner corpuscles are innervated by two mechanoreceptor subtypes that exhibit distinct responses to tactile stimuli. The anatomical receptive fields of these two mechanoreceptor subtypes homotypically tile glabrous skin in a manner that is offset with respect to one another. Electron microscopic analysis of the two Meissner afferents within the corpuscle supports a model in which the extent of lamellar cell wrappings of mechanoreceptor endings determines their force sensitivity thresholds and kinetic properties.
@article{science2020, author = {Neubarth, Nicole L. and Emanuel, Alan J. and Liu, Yin and Springel, Mark W. and Handler, Annie and Zhang, Qiyu and Lehnert, Brendan P. and Guo, Chong and Orefice, Lauren L. and Abdelaziz, Amira and DeLisle, Michelle M. and Iskols, Michael and Rhyins, Julia and Kim, Soo J. and Cattel, Stuart J. and Regehr, Wade and Harvey, Christopher D. and Drugowitsch, Jan and Ginty, David D.}, title = {Meissner corpuscles and their spatially intermingled afferents underlie gentle touch perception}, journal = {Science}, volume = {368}, number = {6497}, pages = {eabb2751}, year = {2020}, month = jun, doi = {10.1126/science.abb2751}, url = {https://www.science.org/doi/abs/10.1126/science.abb2751}, } - NatComms
 The impact of learning on perceptual decisions and its implication for speed-accuracy tradeoffsAndré G. Mendonça, Jan Drugowitsch, M. Inês Vicente, Eric E. J. DeWitt, Alexandre Pouget, and Zachary F. MainenNature Communications, Jun 2020
The impact of learning on perceptual decisions and its implication for speed-accuracy tradeoffsAndré G. Mendonça, Jan Drugowitsch, M. Inês Vicente, Eric E. J. DeWitt, Alexandre Pouget, and Zachary F. MainenNature Communications, Jun 2020The Meissner corpuscle, a mechanosensory end organ, was discovered more than 165 years ago and has since been found in the glabrous skin of all mammals, including that on human fingertips. Although prominently featured in textbooks, the function of the Meissner corpuscle is unknown. Neubarth et al. generated adult mice without Meissner corpuscles and used them to show that these corpuscles alone mediate behavioral responses to, and perception of, gentle forces (see the Perspective by Marshall and Patapoutian). Each Meissner corpuscle is innervated by two molecularly distinct, yet physiologically similar, mechanosensory neurons. These two neuronal subtypes are developmentally interdependent and their endings are intertwined within the corpuscle. Both Meissner mechanosensory neuron subtypes are homotypically tiled, ensuring uniform and complete coverage of the skin, yet their receptive fields are overlapping and offset with respect to each other. Science, this issue p. eabb2751; see also p. 1311 Light touch perception and fine sensorimotor control arise from spatially overlapping mechanoreceptors of the Meissner corpuscle. Meissner corpuscles are mechanosensory end organs that densely occupy mammalian glabrous skin. We generated mice that selectively lacked Meissner corpuscles and found them to be deficient in both perceiving the gentlest detectable forces acting on glabrous skin and fine sensorimotor control. We found that Meissner corpuscles are innervated by two mechanoreceptor subtypes that exhibit distinct responses to tactile stimuli. The anatomical receptive fields of these two mechanoreceptor subtypes homotypically tile glabrous skin in a manner that is offset with respect to one another. Electron microscopic analysis of the two Meissner afferents within the corpuscle supports a model in which the extent of lamellar cell wrappings of mechanoreceptor endings determines their force sensitivity thresholds and kinetic properties.
@article{natcomms2020, author = {Mendonça, André G. and Drugowitsch, Jan and Vicente, M. Inês and DeWitt, Eric E. J. and Pouget, Alexandre and Mainen, Zachary F.}, title = {The impact of learning on perceptual decisions and its implication for speed-accuracy tradeoffs}, journal = {Nature Communications}, volume = {11}, number = {2757}, pages = {1--15}, year = {2020}, doi = {10.1038/s41467-020-16196-7}, url = {https://doi.org/10.1038/s41467-020-16196-7}, eprint = {https://doi.org/10.1038/s41467-020-16196-7}, } - NeurIPS
 Adaptation Properties Allow Identification of Optimized Neural CodesLuke Rast, and Jan DrugowitschIn Advances in Neural Information Processing Systems, Jun 2020
Adaptation Properties Allow Identification of Optimized Neural CodesLuke Rast, and Jan DrugowitschIn Advances in Neural Information Processing Systems, Jun 2020The adaptation of neural codes to the statistics of their environment is well captured by efficient coding approaches. Here we solve an inverse problem: characterizing the objective and constraint functions that efficient codes appear to be optimal for, on the basis of how they adapt to different stimulus distributions. We formulate a general efficient coding problem, with flexible objective and constraint functions and minimal parametric assumptions. Solving special cases of this model, we provide solutions to broad classes of Fisher information-based efficient coding problems, generalizing a wide range of previous results. We show that different objective function types impose qualitatively different adaptation behaviors, while constraints enforce characteristic deviations from classic efficient coding signatures. Despite interaction between these effects, clear signatures emerge for both unconstrained optimization problems and information-maximizing objective functions. Asking for a fixed-point of the neural code adaptation, we find an objective-independent characterization of constraints on the neural code. We use this result to propose an experimental paradigm that can characterize both the objective and constraint functions that an observed code appears to be optimized for.
@inproceedings{neurips2020, author = {Rast, Luke and Drugowitsch, Jan}, booktitle = {Advances in Neural Information Processing Systems}, editor = {Larochelle, H. and Ranzato, M. and Hadsell, R. and Balcan, M.F. and Lin, H.}, pages = {1142--1152}, publisher = {Curran Associates, Inc.}, title = {Adaptation Properties Allow Identification of Optimized Neural Codes}, volume = {33}, year = {2020}, }






2019
- PNAS
 Learning optimal decisions with confidenceJan Drugowitsch, André G. Mendonça, Zachary F. Mainen, and Alexandre PougetProceedings of the National Academy of Sciences, Nov 2019
Learning optimal decisions with confidenceJan Drugowitsch, André G. Mendonça, Zachary F. Mainen, and Alexandre PougetProceedings of the National Academy of Sciences, Nov 2019Diffusion decision models (DDMs) are immensely successful models for decision making under uncertainty and time pressure. In the context of perceptual decision making, these models typically start with two input units, organized in a neuron–antineuron pair. In contrast, in the brain, sensory inputs are encoded through the activity of large neuronal populations. Moreover, while DDMs are wired by hand, the nervous system must learn the weights of the network through trial and error. There is currently no normative theory of learning in DDMs and therefore no theory of how decision makers could learn to make optimal decisions in this context. Here, we derive such a rule for learning a near-optimal linear combination of DDM inputs based on trial-by-trial feedback. The rule is Bayesian in the sense that it learns not only the mean of the weights but also the uncertainty around this mean in the form of a covariance matrix. In this rule, the rate of learning is proportional (respectively, inversely proportional) to confidence for incorrect (respectively, correct) decisions. Furthermore, we show that, in volatile environments, the rule predicts a bias toward repeating the same choice after correct decisions, with a bias strength that is modulated by the previous choice’s difficulty. Finally, we extend our learning rule to cases for which one of the choices is more likely a priori, which provides insights into how such biases modulate the mechanisms leading to optimal decisions in diffusion models.
@article{pnas2019, author = {Drugowitsch, Jan and Mendonça, André G. and Mainen, Zachary F. and Pouget, Alexandre}, title = {Learning optimal decisions with confidence}, journal = {Proceedings of the National Academy of Sciences}, volume = {116}, number = {49}, pages = {24872-24880}, year = {2019}, month = nov, doi = {10.1073/pnas.1906787116}, url = {https://www.pnas.org/doi/abs/10.1073/pnas.1906787116}, } - PhysRevE
 Family of closed-form solutions for two-dimensional correlated diffusion processesHaozhe Shan, Rubén Moreno-Bote, and Jan DrugowitschPhysical Review E, Sep 2019
Family of closed-form solutions for two-dimensional correlated diffusion processesHaozhe Shan, Rubén Moreno-Bote, and Jan DrugowitschPhysical Review E, Sep 2019Diffusion processes with boundaries are models of transport phenomena with wide applicability across many fields. These processes are described by their probability density functions (PDFs), which often obey Fokker-Planck equations (FPEs). While obtaining analytical solutions is often possible in the absence of boundaries, obtaining closed-form solutions to the FPE is more challenging once absorbing boundaries are present. As a result, analyses of these processes have largely relied on approximations or direct simulations. In this paper, we studied two-dimensional, time-homogeneous, spatially correlated diffusion with linear, axis-aligned, absorbing boundaries. Our main result is the explicit construction of a full family of closed-form solutions for their PDFs using the method of images. We found that such solutions can be built if and only if the correlation coefficient ρ between the two diffusing processes takes one of a numerable set of values. Using a geometric argument, we derived the complete set of ρ’s where such solutions can be found. Solvable ρ’s are given by ρ=−cos(π/k), where k ∈ Z+ ∪ +∞. Solutions were validated in simulations. Qualitative behaviors of the process appear to vary smoothly over ρ, allowing extrapolation from our solutions to cases with unsolvable ρ’s.
@article{physreve2019, title = {Family of closed-form solutions for two-dimensional correlated diffusion processes}, author = {Shan, Haozhe and Moreno-Bote, Rub\'en and Drugowitsch, Jan}, journal = {Physical Review E}, volume = {100}, issue = {3}, pages = {032132}, numpages = {10}, year = {2019}, month = sep, publisher = {American Physical Society}, doi = {10.1103/PhysRevE.100.032132}, url = {https://link.aps.org/doi/10.1103/PhysRevE.100.032132}, } - Neuron
 Control of Synaptic Specificity by Establishing a Relative Preference for Synaptic PartnersChundi Xu, Emma Theisen, Ryan Maloney, Jing Peng, Ivan Santiago, Clarence Yapp, Zachary Werkhoven, Elijah Rumbaut, and 11 more authorsNeuron, Sep 2019
Control of Synaptic Specificity by Establishing a Relative Preference for Synaptic PartnersChundi Xu, Emma Theisen, Ryan Maloney, Jing Peng, Ivan Santiago, Clarence Yapp, Zachary Werkhoven, Elijah Rumbaut, and 11 more authorsNeuron, Sep 2019The ability of neurons to identify correct synaptic partners is fundamental to the proper assembly and function of neural circuits. Relative to other steps in circuit formation such as axon guidance, our knowledge of how synaptic partner selection is regulated is severely limited. Drosophila Dpr and DIP immunoglobulin superfamily (IgSF) cell-surface proteins bind heterophilically and are expressed in a complementary manner between synaptic partners in the visual system. Here, we show that in the lamina, DIP mis-expression is sufficient to promote synapse formation with Dpr-expressing neurons and that disrupting DIP function results in ectopic synapse formation. These findings indicate that DIP proteins promote synapses to form between specific cell types and that in their absence, neurons synapse with alternative partners. We propose that neurons have the capacity to synapse with a broad range of cell types and that synaptic specificity is achieved by establishing a preference for specific partners.
@article{neuron2019, title = {Control of Synaptic Specificity by Establishing a Relative Preference for Synaptic Partners}, journal = {Neuron}, volume = {103}, number = {5}, pages = {865-877.e7}, year = {2019}, month = sep, issn = {0896-6273}, doi = {10.1016/j.neuron.2019.06.006}, url = {https://www.sciencedirect.com/science/article/pii/S0896627319305562}, author = {Xu, Chundi and Theisen, Emma and Maloney, Ryan and Peng, Jing and Santiago, Ivan and Yapp, Clarence and Werkhoven, Zachary and Rumbaut, Elijah and Shum, Bryan and Tarnogorska, Dorota and Borycz, Jolanta and Tan, Liming and Courgeon, Maximilien and Griffin, Tessa and Levin, Raina and Meinertzhagen, Ian A. and {de Bivort}, Benjamin and Drugowitsch, Jan and Pecot, Matthew Y.}, keywords = {synaptic specificity, synapse formation, cell recognition molecules, visual system, Dpr and DIP proteins}, } - NatNeuro
 Optimal policy for multi-alternative decisionsSatohiro Tajima, Jan Drugowitsch, Nisheet Patel, and Alexandre PougetNature Neuroscience, Sep 2019
Optimal policy for multi-alternative decisionsSatohiro Tajima, Jan Drugowitsch, Nisheet Patel, and Alexandre PougetNature Neuroscience, Sep 2019Everyday decisions frequently require choosing among multiple alternatives. Yet the optimal policy for such decisions is unknown. Here we derive the normative policy for general multi-alternative decisions. This strategy requires evidence accumulation to nonlinear, time-dependent bounds that trigger choices. A geometric symmetry in those boundaries allows the optimal strategy to be implemented by a simple neural circuit involving normalization with fixed decision bounds and an urgency signal. The model captures several key features of the response of decision-making neurons as well as the increase in reaction time as a function of the number of alternatives, known as Hick’s law. In addition, we show that in the presence of divisive normalization and internal variability, our model can account for several so-called ‘irrational’ behaviors, such as the similarity effect as well as the violation of both the independence of irrelevant alternatives principle and the regularity principle.
@article{natneuro2019, title = {Optimal policy for multi-alternative decisions}, author = {Tajima, Satohiro and Drugowitsch, Jan and Patel, Nisheet and Pouget, Alexandre}, journal = {Nature Neuroscience}, volume = {22}, pages = {1503--1511}, year = {2019}, month = sep, doi = {10.1038/s41593-019-0453-9}, url = {https://doi.org/10.1038/s41593-019-0453-9}, } - JOSS
 VBLinLogit: Variational Bayesian linear and logistic regressionJan DrugowitschJournal of Open Source Software, Sep 2019
VBLinLogit: Variational Bayesian linear and logistic regressionJan DrugowitschJournal of Open Source Software, Sep 2019@article{joss2019, doi = {10.21105/joss.01359}, url = {https://doi.org/10.21105/joss.01359}, year = {2019}, publisher = {The Open Journal}, volume = {4}, number = {38}, pages = {1359}, author = {Drugowitsch, Jan}, title = {VBLinLogit: Variational Bayesian linear and logistic regression}, journal = {Journal of Open Source Software}, } - NatComms
 Prefrontal mechanisms combining rewards and beliefs in human decision-makingMarion Rouault, Jan Drugowitsch, and Etienne KoechlinNature Communications, Jan 2019
Prefrontal mechanisms combining rewards and beliefs in human decision-makingMarion Rouault, Jan Drugowitsch, and Etienne KoechlinNature Communications, Jan 2019In uncertain and changing environments, optimal decision-making requires integrating reward expectations with probabilistic beliefs about reward contingencies. Little is known, however, about how the prefrontal cortex (PFC), which subserves decision-making, combines these quantities. Here, using computational modelling and neuroimaging, we show that the ventromedial PFC encodes both reward expectations and proper beliefs about reward contingencies, while the dorsomedial PFC combines these quantities and guides choices that are at variance with those predicted by optimal decision theory: instead of integrating reward expectations with beliefs, the dorsomedial PFC built context-dependent reward expectations commensurable to beliefs and used these quantities as two concurrent appetitive components, driving choices. This neural mechanism accounts for well-known risk aversion effects in human decision-making. The results reveal that the irrationality of human choices commonly theorized as deriving from optimal computations over false beliefs, actually stems from suboptimal neural heuristics over rational beliefs about reward contingencies.
@article{natcomms2019, title = {Prefrontal mechanisms combining rewards and beliefs in human decision-making}, author = {Rouault, Marion and Drugowitsch, Jan and Koechlin, Etienne}, journal = {Nature Communications}, volume = {10}, pages = {301}, year = {2019}, month = jan, doi = {10.1038/s41467-018-08121-w}, url = {https://doi.org/10.1038/s41467-018-08121-w}, }






2017
- NatComms
 Lateral orbitofrontal cortex anticipates choices and integrates prior with current informationRamon Nogueira, Juan M. Abolafia, Jan Drugowitsch, Emili Balaguer-Ballester, Maria V. Sanchez-Vives, and Rubén Moreno-BoteNature Communications, Mar 2017
Lateral orbitofrontal cortex anticipates choices and integrates prior with current informationRamon Nogueira, Juan M. Abolafia, Jan Drugowitsch, Emili Balaguer-Ballester, Maria V. Sanchez-Vives, and Rubén Moreno-BoteNature Communications, Mar 2017Adaptive behavior requires integrating prior with current information to anticipate upcoming events. Brain structures related to this computation should bring relevant signals from the recent past into the present. Here we report that rats can integrate the most recent prior information with sensory information, thereby improving behavior on a perceptual decision-making task with outcome-dependent past trial history. We find that anticipatory signals in the orbitofrontal cortex about upcoming choice increase over time and are even present before stimulus onset. These neuronal signals also represent the stimulus and relevant second-order combinations of past state variables. The encoding of choice, stimulus and second-order past state variables resides, up to movement onset, in overlapping populations. The neuronal representation of choice before stimulus onset and its build-up once the stimulus is presented suggest that orbitofrontal cortex plays a role in transforming immediate prior and stimulus information into choices using a compact state-space representation.
@article{natcomms2017, title = {Lateral orbitofrontal cortex anticipates choices and integrates prior with current information}, author = {Nogueira, Ramon and Abolafia, Juan M. and Drugowitsch, Jan and Balaguer-Ballester, Emili and Sanchez-Vives, Maria V. and Moreno-Bote, Rubén}, journal = {Nature Communications}, volume = {8}, pages = {14823}, year = {2017}, month = mar, doi = {10.1038/ncomms14823}, url = {https://doi.org/10.1038/ncomms14823}, }

2016
- Neuron
 Computational Precision of Mental Inference as Critical Source of Human Choice SuboptimalityJan Drugowitsch, Valentin Wyart, Anne-Dominique Devauchelle, and Etienne KoechlinNeuron, Mar 2016
Computational Precision of Mental Inference as Critical Source of Human Choice SuboptimalityJan Drugowitsch, Valentin Wyart, Anne-Dominique Devauchelle, and Etienne KoechlinNeuron, Mar 2016Making decisions in uncertain environments often requires combining multiple pieces of ambiguous information from external cues. In such conditions, human choices resemble optimal Bayesian inference, but typically show a large suboptimal variability whose origin remains poorly understood. In particular, this choice suboptimality might arise from imperfections in mental inference rather than in peripheral stages, such as sensory processing and response selection. Here, we dissociate these three sources of suboptimality in human choices based on combining multiple ambiguous cues. Using a novel quantitative approach for identifying the origin and structure of choice variability, we show that imperfections in inference alone cause a dominant fraction of suboptimal choices. Furthermore, two-thirds of this suboptimality appear to derive from the limited precision of neural computations implementing inference rather than from systematic deviations from Bayes-optimal inference. These findings set an upper bound on the accuracy and ultimate predictability of human choices in uncertain environments.
@article{neuron2016c, title = {Computational Precision of Mental Inference as Critical Source of Human Choice Suboptimality}, journal = {Neuron}, volume = {92}, number = {6}, pages = {1398-1411}, year = {2016}, issn = {0896-6273}, doi = {https://doi.org/10.1016/j.neuron.2016.11.005}, url = {https://www.sciencedirect.com/science/article/pii/S0896627316308431}, author = {Drugowitsch, Jan and Wyart, Valentin and Devauchelle, Anne-Dominique and Koechlin, Etienne}, keywords = {decision-making, variability, computational models, probabilistic inference}, } - NatComms
 Optimal policy for value-based decision-makingSatohiro Tajima, Jan Drugowitsch, and Alexandre PougetNature Communications, Aug 2016
Optimal policy for value-based decision-makingSatohiro Tajima, Jan Drugowitsch, and Alexandre PougetNature Communications, Aug 2016For decades now, normative theories of perceptual decisions, and their implementation as drift diffusion models, have driven and significantly improved our understanding of human and animal behaviour and the underlying neural processes. While similar processes seem to govern value-based decisions, we still lack the theoretical understanding of why this ought to be the case. Here, we show that, similar to perceptual decisions, drift diffusion models implement the optimal strategy for value-based decisions. Such optimal decisions require the models’ decision boundaries to collapse over time, and to depend on the a priori knowledge about reward contingencies. Diffusion models only implement the optimal strategy under specific task assumptions, and cease to be optimal once we start relaxing these assumptions, by, for example, using non-linear utility functions. Our findings thus provide the much-needed theory for value-based decisions, explain the apparent similarity to perceptual decisions, and predict conditions under which this similarity should break down.
@article{natcomms2016, title = {Optimal policy for value-based decision-making}, author = {Tajima, Satohiro and Drugowitsch, Jan and Pouget, Alexandre}, journal = {Nature Communications}, volume = {7}, pages = {12400}, year = {2016}, month = aug, doi = {10.1038/ncomms12400}, url = {https://doi.org/10.1038/ncomms12400}, } - Neuron
 Becoming Confident in the Statistical Nature of Human Confidence JudgmentsJan DrugowitschNeuron, Aug 2016
Becoming Confident in the Statistical Nature of Human Confidence JudgmentsJan DrugowitschNeuron, Aug 2016In this issue of Neuron, Sanders et al. (2016) demonstrate that human confidence judgments seem to arise from computations compatible with statistical decision theory, shining a new light on the old questions of how such judgments are formed.
@article{neuron2016b, title = {Becoming Confident in the Statistical Nature of Human Confidence Judgments}, journal = {Neuron}, volume = {90}, number = {3}, pages = {425-427}, year = {2016}, issn = {0896-6273}, doi = {10.1016/j.neuron.2016.04.023}, url = {https://www.sciencedirect.com/science/article/pii/S0896627316301106}, author = {Drugowitsch, Jan}, keywords = {confidence, decision making, uncertainty, Bayesian models}, } - NatNeuro
 Confidence and certainty: distinct probabilistic quantities for different goalsAlexandre Pouget, Jan Drugowitsch, and Adam KepecsNature Neuroscience, Aug 2016
Confidence and certainty: distinct probabilistic quantities for different goalsAlexandre Pouget, Jan Drugowitsch, and Adam KepecsNature Neuroscience, Aug 2016The authors use recent probabilistic theories of neural computation to argue that confidence and certainty are not identical concepts. They propose precise mathematical definitions for both of these concepts and discuss putative neural representations.
@article{natneuro2016, title = {Confidence and certainty: distinct probabilistic quantities for different goals}, journal = {Nature Neuroscience}, volume = {19}, number = {3}, pages = {366--374}, year = {2016}, doi = {10.1038/nn.4240}, url = {https://doi.org/10.1038/nn.4240}, author = {Pouget, Alexandre and Drugowitsch, Jan and Kepecs, Adam}, keywords = {confidence, decision making, uncertainty, Bayesian models}, } - NatNeuro
 Fast and accurate Monte Carlo sampling of first-passage times from Wiener diffusion modelsJan DrugowitschScientific Reports, Feb 2016
Fast and accurate Monte Carlo sampling of first-passage times from Wiener diffusion modelsJan DrugowitschScientific Reports, Feb 2016We present a new, fast approach for drawing boundary crossing samples from Wiener diffusion models. Diffusion models are widely applied to model choices and reaction times in two-choice decisions. Samples from these models can be used to simulate the choices and reaction times they predict. These samples, in turn, can be utilized to adjust the models’ parameters to match observed behavior from humans and other animals. Usually, such samples are drawn by simulating a stochastic differential equation in discrete time steps, which is slow and leads to biases in the reaction time estimates. Our method, instead, facilitates known expressions for first-passage time densities, which results in unbiased, exact samples and a hundred to thousand-fold speed increase in typical situations. In its most basic form it is restricted to diffusion models with symmetric boundaries and non-leaky accumulation, but our approach can be extended to also handle asymmetric boundaries or to approximate leaky accumulation.
@article{scirep2016, title = {Fast and accurate Monte Carlo sampling of first-passage times from Wiener diffusion models}, journal = {Scientific Reports}, volume = {6}, pages = {20490}, year = {2016}, month = feb, doi = {10.1038/srep20490}, url = {https://doi.org/10.1038/srep20490}, author = {Drugowitsch, Jan}, } - Neuron
 Multiplicative and Additive Modulation of Neuronal Tuning with Population Activity Affects Encoded InformationIñigo Arandia-Romero, Seiji Tanabe, Jan Drugowitsch, Adam Kohn, and Rubén Moreno-BoteNeuron, Mar 2016
Multiplicative and Additive Modulation of Neuronal Tuning with Population Activity Affects Encoded InformationIñigo Arandia-Romero, Seiji Tanabe, Jan Drugowitsch, Adam Kohn, and Rubén Moreno-BoteNeuron, Mar 2016Numerous studies have shown that neuronal responses are modulated by stimulus properties and also by the state of the local network. However, little is known about how activity fluctuations of neuronal populations modulate the sensory tuning of cells and affect their encoded information. We found that fluctuations in ongoing and stimulus-evoked population activity in primate visual cortex modulate the tuning of neurons in a multiplicative and additive manner. While distributed on a continuum, neurons with stronger multiplicative effects tended to have less additive modulation and vice versa. The information encoded by multiplicatively modulated neurons increased with greater population activity, while that of additively modulated neurons decreased. These effects offset each other so that population activity had little effect on total information. Our results thus suggest that intrinsic activity fluctuations may act as a “traffic light” that determines which subset of neurons is most informative.
@article{neuron2016a, journal = {Neuron}, volume = {89}, number = {6}, pages = {1305-1316}, year = {2016}, month = mar, issn = {0896-6273}, doi = {https://doi.org/10.1016/j.neuron.2016.01.044}, url = {https://www.sciencedirect.com/science/article/pii/S089662731600091X}, author = {Arandia-Romero, Iñigo and Tanabe, Seiji and Drugowitsch, Jan and Kohn, Adam and Moreno-Bote, Rubén}, }






2015
- SciRep
 Causal Inference and Explaining Away in a Spiking NetworkRubén Moreno-Bote, and Jan DrugowitschScientific Reports, Dec 2015
Causal Inference and Explaining Away in a Spiking NetworkRubén Moreno-Bote, and Jan DrugowitschScientific Reports, Dec 2015While the brain uses spiking neurons for communication, theoretical research on brain computations has mostly focused on non-spiking networks. The nature of spike-based algorithms that achieve complex computations, such as object probabilistic inference, is largely unknown. Here we demonstrate that a family of high-dimensional quadratic optimization problems with non-negativity constraints can be solved exactly and efficiently by a network of spiking neurons. The network naturally imposes the non-negativity of causal contributions that is fundamental to causal inference and uses simple operations, such as linear synapses with realistic time constants and neural spike generation and reset non-linearities. The network infers the set of most likely causes from an observation using explaining away, which is dynamically implemented by spike-based, tuned inhibition. The algorithm performs remarkably well even when the network intrinsically generates variable spike trains, the timing of spikes is scrambled by external sources of noise, or the network is mistuned. This type of network might underlie tasks such as odor identification and classification.
@article{scirep2015, title = {Causal Inference and Explaining Away in a Spiking Network}, journal = {Scientific Reports}, volume = {5}, pages = {17531}, year = {2015}, month = dec, doi = {10.1038/srep17531}, url = {https://doi.org/10.1038/srep17531}, author = {Moreno-Bote, Rubén and Drugowitsch, Jan}, } - FNCom
 Simultaneous Learning and Filtering without Delusions: A Bayes-Optimal Derivation of Combining Predictive Inference and Adaptive FilteringJan Kneissler, Jan Drugowitsch, Karl Friston, and Martin ButzFrontiers in Computational Neuroscience, Dec 2015
Simultaneous Learning and Filtering without Delusions: A Bayes-Optimal Derivation of Combining Predictive Inference and Adaptive FilteringJan Kneissler, Jan Drugowitsch, Karl Friston, and Martin ButzFrontiers in Computational Neuroscience, Dec 2015Predictive coding appears to be one of the fundamental working principles of brain processing. Amongst other aspects, brains often predict the sensory consequences of their own actions. Predictive coding resembles Kalman filtering, where incoming sensory information is filtered to produce prediction errors for subsequent adaptation and learning. However, to generate prediction errors given motor commands, a suitable temporal forward model is required to generate predictions. While in engineering applications, it is usually assumed that this forward model is known, the brain has to learn it. When filtering sensory input and learning from the residual signal in parallel, a fundamental problem arises: the system can enter a delusional loop when filtering the sensory information using an overly trusted forward model. In this case, learning stalls before accurate convergence because uncertainty about the forward model is not properly accommodated. We present a Bayes-optimal solution to this generic and pernicious problem for the case of linear forward models, which we call Predictive Inference and Adaptive Filtering (PIAF). PIAF filters incoming sensory information and learns the forward model simultaneously. We show that PIAF is formally related to Kalman filtering and to the Recursive Least Squares linear approximation method, but combines these procedures in a Bayes optimal fashion. Numerical evaluations confirm that the delusional loop is precluded and that the learning of the forward model is more than 10-times faster when compared to a naive combination of Kalman filtering and Recursive Least Squares.
@article{fncom2015, author = {Kneissler, Jan and Drugowitsch, Jan and Friston, Karl and Butz, Martin}, title = {Simultaneous Learning and Filtering without Delusions: A Bayes-Optimal Derivation of Combining Predictive Inference and Adaptive Filtering}, journal = {Frontiers in Computational Neuroscience}, volume = {9}, year = {2015}, url = {https://www.frontiersin.org/articles/10.3389/fncom.2015.00047}, doi = {10.3389/fncom.2015.00047}, issn = {1662-5188}, } - eLife
 Tuning the speed-accuracy trade-off to maximize reward rate in multisensory decision-makingJan Drugowitsch, Gregory C DeAngelis, Dora E Angelaki, and Alexandre PougeteLife, Jun 2015
Tuning the speed-accuracy trade-off to maximize reward rate in multisensory decision-makingJan Drugowitsch, Gregory C DeAngelis, Dora E Angelaki, and Alexandre PougeteLife, Jun 2015For decisions made under time pressure, effective decision making based on uncertain or ambiguous evidence requires efficient accumulation of evidence over time, as well as appropriately balancing speed and accuracy, known as the speed/accuracy trade-off. For simple unimodal stimuli, previous studies have shown that human subjects set their speed/accuracy trade-off to maximize reward rate. We extend this analysis to situations in which information is provided by multiple sensory modalities. Analyzing previously collected data (Drugowitsch et al., 2014), we show that human subjects adjust their speed/accuracy trade-off to produce near-optimal reward rates. This trade-off can change rapidly across trials according to the sensory modalities involved, suggesting that it is represented by neural population codes rather than implemented by slow neuronal mechanisms such as gradual changes in synaptic weights. Furthermore, we show that deviations from the optimal speed/accuracy trade-off can be explained by assuming an incomplete gradient-based learning of these trade-offs.
@article{eLife2015, article_type = {journal}, title = {Tuning the speed-accuracy trade-off to maximize reward rate in multisensory decision-making}, author = {Drugowitsch, Jan and DeAngelis, Gregory C and Angelaki, Dora E and Pouget, Alexandre}, editor = {Behrens, Timothy}, volume = {4}, year = {2015}, month = jun, pub_date = {2015-06-19}, pages = {e06678}, citation = {eLife 2015;4:e06678}, doi = {10.7554/eLife.06678}, url = {https://doi.org/10.7554/eLife.06678}, keywords = {speed-accuracy trade-off, decision-making, multisensory integration, optimality}, journal = {eLife}, issn = {2050-084X}, publisher = {eLife Sciences Publications, Ltd}, }



2014
- NeurIPS
 Optimal decision-making with time-varying evidence reliabilityJan Drugowitsch, Ruben Moreno-Bote, and Alexandre PougetIn Advances in Neural Information Processing Systems, Jun 2014
Optimal decision-making with time-varying evidence reliabilityJan Drugowitsch, Ruben Moreno-Bote, and Alexandre PougetIn Advances in Neural Information Processing Systems, Jun 2014Previous theoretical and experimental work on optimal decision-making was restricted to the artificial setting of a reliability of the momentary sensory evidence that remained constant within single trials. The work presented here describes the computation and characterization of optimal decision-making in the more realistic case of an evidence reliability that varies across time even within a trial. It shows that, in this case, the optimal behavior is determined by a bound in the decision maker’s belief that depends only on the current, but not the past, reliability. We furthermore demonstrate that simpler heuristics fail to match the optimal performance for certain characteristics of the process that determines the time-course of this reliability, causing a drop in reward rate by more than 50%.
@inproceedings{neurips2014, author = {Drugowitsch, Jan and Moreno-Bote, Ruben and Pouget, Alexandre}, booktitle = {Advances in Neural Information Processing Systems}, editor = {Ghahramani, Z. and Welling, M. and Cortes, C. and Lawrence, N. and Weinberger, K.Q.}, pages = {}, publisher = {Curran Associates, Inc.}, title = {Optimal decision-making with time-varying evidence reliability}, volume = {27}, year = {2014}, } - eLife
 Optimal multisensory decision-making in a reaction-time taskJan Drugowitsch, Gregory C DeAngelis, Eliana M Klier, Dora E Angelaki, and Alexandre PougeteLife, Jun 2014
Optimal multisensory decision-making in a reaction-time taskJan Drugowitsch, Gregory C DeAngelis, Eliana M Klier, Dora E Angelaki, and Alexandre PougeteLife, Jun 2014Humans and animals can integrate sensory evidence from various sources to make decisions in a statistically near-optimal manner, provided that the stimulus presentation time is fixed across trials. Little is known about whether optimality is preserved when subjects can choose when to make a decision (reaction-time task), nor when sensory inputs have time-varying reliability. Using a reaction-time version of a visual/vestibular heading discrimination task, we show that behavior is clearly sub-optimal when quantified with traditional optimality metrics that ignore reaction times. We created a computational model that accumulates evidence optimally across both cues and time, and trades off accuracy with decision speed. This model quantitatively explains subjects’s choices and reaction times, supporting the hypothesis that subjects do, in fact, accumulate evidence optimally over time and across sensory modalities, even when the reaction time is under the subject’s control.
@article{elife2014, article_type = {journal}, title = {Optimal multisensory decision-making in a reaction-time task}, author = {Drugowitsch, Jan and DeAngelis, Gregory C and Klier, Eliana M and Angelaki, Dora E and Pouget, Alexandre}, editor = {Marder, Eve}, volume = {3}, year = {2014}, month = jun, pub_date = {2014-06-14}, pages = {e03005}, citation = {eLife 2014;3:e03005}, doi = {10.7554/eLife.03005}, url = {https://doi.org/10.7554/eLife.03005}, keywords = {decision-making, cue combination, reaction time, diffusion model}, journal = {eLife}, issn = {2050-084X}, publisher = {eLife Sciences Publications, Ltd}, } - PLoS ONE
 Relation between Belief and Performance in Perceptual Decision MakingJan Drugowitsch, Ruben Moreno-Bote, and Alexandre PougetPLoS ONE, May 2014
Relation between Belief and Performance in Perceptual Decision MakingJan Drugowitsch, Ruben Moreno-Bote, and Alexandre PougetPLoS ONE, May 2014In an uncertain and ambiguous world, effective decision making requires that subjects form and maintain a belief about the correctness of their choices, a process called meta-cognition. Prediction of future outcomes and self-monitoring are only effective if belief closely matches behavioral performance. Equality between belief and performance is also critical for experimentalists to gain insight into the subjects’ belief by simply measuring their performance. Assuming that the decision maker holds the correct model of the world, one might indeed expect that belief and performance should go hand in hand. Unfortunately, we show here that this is rarely the case when performance is defined as the percentage of correct responses for a fixed stimulus, a standard definition in psychophysics. In this case, belief equals performance only for a very narrow family of tasks, whereas in others they will only be very weakly correlated. As we will see it is possible to restore this equality in specific circumstances but this remedy is only effective for a decision-maker, not for an experimenter. We furthermore show that belief and performance do not match when conditioned on task difficulty – as is common practice when plotting the psychometric curve – highlighting common pitfalls in previous neuroscience work. Finally, we demonstrate that miscalibration and the hard-easy effect observed in humans’ and other animals’ certainty judgments could be explained by a mismatch between the experimenter’s and decision maker’s expected distribution of task difficulties. These results have important implications for experimental design and are of relevance for theories that aim to unravel the nature of meta-cognition.
@article{plosone2014, title = {Relation between Belief and Performance in Perceptual Decision Making}, author = {Drugowitsch, Jan and Moreno-Bote, Ruben and Pouget, Alexandre}, editor = {Hamed, Suliann Ben}, volume = {9}, issue = {5}, year = {2014}, month = may, pages = {e96511}, doi = {10.1371/journal.pone.0096511}, url = {https://doi.org/10.1371/journal.pone.0096511}, journal = {PLoS ONE}, } - EVCO
 Filtering Sensory Information with XCSF: Improving Learning Robustness and Robot Arm Control PerformanceJan Kneissler, Patrick O. Stalph, Jan Drugowitsch, and Martin V. ButzEvolutionary Computation, Mar 2014
Filtering Sensory Information with XCSF: Improving Learning Robustness and Robot Arm Control PerformanceJan Kneissler, Patrick O. Stalph, Jan Drugowitsch, and Martin V. ButzEvolutionary Computation, Mar 2014It has been shown previously that the control of a robot arm can be efficiently learned using the XCSF learning classifier system, which is a nonlinear regression system based on evolutionary computation. So far, however, the predictive knowledge about how actual motor activity changes the state of the arm system has not been exploited. In this paper, we utilize the forward velocity kinematics knowledge of XCSF to alleviate the negative effect of noisy sensors for successful learning and control. We incorporate Kalman filtering for estimating successive arm positions, iteratively combining sensory readings with XCSF-based predictions of hand position changes over time. The filtered arm position is used to improve both trajectory planning and further learning of the forward velocity kinematics. We test the approach on a simulated kinematic robot arm model. The results show that the combination can improve learning and control performance significantly. However, it also shows that variance estimates of XCSF prediction may be underestimated, in which case self-delusional spiraling effects can hinder effective learning. Thus, we introduce a heuristic parameter, which can be motivated by theory, and which limits the influence of XCSF’s predictions on its own further learning input. As a result, we obtain drastic improvements in noise tolerance, allowing the system to cope with more than 10-times higher noise levels.
@article{evco2014, author = {Kneissler, Jan and Stalph, Patrick O. and Drugowitsch, Jan and Butz, Martin V.}, title = {Filtering Sensory Information with XCSF: Improving Learning Robustness and Robot Arm Control Performance}, journal = {Evolutionary Computation}, volume = {22}, number = {1}, pages = {139-158}, year = {2014}, month = mar, issn = {1063-6560}, doi = {10.1162/EVCO_a_00108}, url = {https://doi.org/10.1162/EVCO\_a\_00108}, }




2013
- arXiv
 Variational Bayesian inference for linear and logistic regressionJan DrugowitschArXiv e-prints, Oct 2013
Variational Bayesian inference for linear and logistic regressionJan DrugowitschArXiv e-prints, Oct 2013The article describe the model, derivation, and implementation of variational Bayesian inference for linear and logistic regression, both with and without automatic relevance determination. It has the dual function of acting as a tutorial for the derivation of variational Bayesian inference for simple models, as well as documenting, and providing brief examples for the MATLAB/Octave functions that implement this inference. These functions are freely available online.
author = {Drugowitsch, Jan}, title = {Variational Bayesian inference for linear and logistic regression}, journal = {ArXiv e-prints}, archiveprefix = {arXiv}, eprint = {1310.5438}, primaryclass = {stat.ML}, year = {2013}, month = oct, doi = {10.48550/arXiv.1310.5438}, }

2012
- GECCO
 Filtering Sensory Information with XCSF: Improving Learning Robustness and Control PerformanceJan Kneissler, Patrick O. Stalph, Jan Drugowitsch, and Martin V. ButzIn Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation, Philadelphia, Pennsylvania, USA, Jul 2012
Filtering Sensory Information with XCSF: Improving Learning Robustness and Control PerformanceJan Kneissler, Patrick O. Stalph, Jan Drugowitsch, and Martin V. ButzIn Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation, Philadelphia, Pennsylvania, USA, Jul 2012It was previously shown that the control of a robot arm can be efficiently learned using the XCSF classifier system. So far, however, the predictive knowledge about how actual motor activity changes the state of the arm system has not been exploited. In this paper, we exploit the forward velocity kinematics knowledge of XCSF to alleviate the negative effect of noisy sensors for successful learning and control. We incorporate Kalman filtering for estimating successive arm positions iteratively combining sensory readings with XCSF-based predictions of hand position changes over time. The filtered arm position is used to improve both trajectory planning and further learning of the forward velocity kinematics. We test the approach on a simulated, kinematic robot arm model. The results show that the combination can improve learning and control performance significantly. However, it also shows that variance estimates of XCSF predictions maybe underestimated, in which case self-delusional spiraling effects hinder effective learning. Thus, we introduce a heuristic parameter, which limits the influence of XCSF’s predictions on its own further learning input. As a result, we obtain drastic improvements in noise tolerance coping with more than ten times higher noise levels.
@inproceedings{gecco2012, author = {Kneissler, Jan and Stalph, Patrick O. and Drugowitsch, Jan and Butz, Martin V.}, title = {Filtering Sensory Information with XCSF: Improving Learning Robustness and Control Performance}, year = {2012}, month = jul, isbn = {9781450311779}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/2330163.2330284}, doi = {10.1145/2330163.2330284}, booktitle = {Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation}, pages = {871–878}, numpages = {8}, keywords = {robotics, function approximation, noise, learning classifier systems, xcsf}, location = {Philadelphia, Pennsylvania, USA}, series = {GECCO '12}, } - JNS
 The Cost of Accumulating Evidence in Perceptual Decision MakingJan Drugowitsch, Rubén Moreno-Bote, Anne K. Churchland, Michael N. Shadlen, and Alexandre PougetJournal of Neuroscience, Mar 2012
The Cost of Accumulating Evidence in Perceptual Decision MakingJan Drugowitsch, Rubén Moreno-Bote, Anne K. Churchland, Michael N. Shadlen, and Alexandre PougetJournal of Neuroscience, Mar 2012Decision making often involves the accumulation of information over time, but acquiring information typically comes at a cost. Little is known about the cost incurred by animals and humans for acquiring additional information from sensory variables due, for instance, to attentional efforts. Through a novel integration of diffusion models and dynamic programming, we were able to estimate the cost of making additional observations per unit of time from two monkeys and six humans in a reaction time (RT) random-dot motion discrimination task. Surprisingly, we find that the cost is neither zero nor constant over time, but for the animals and humans features a brief period in which it is constant but increases thereafter. In addition, we show that our theory accurately matches the observed reaction time distributions for each stimulus condition, the time-dependent choice accuracy both conditional on stimulus strength and independent of it, and choice accuracy and mean reaction times as a function of stimulus strength. The theory also correctly predicts that urgency signals in the brain should be independent of the difficulty, or stimulus strength, at each trial.
@article{jns2012, author = {Drugowitsch, Jan and Moreno-Bote, Rub{\'e}n and Churchland, Anne K. and Shadlen, Michael N. and Pouget, Alexandre}, title = {The Cost of Accumulating Evidence in Perceptual Decision Making}, volume = {32}, number = {11}, pages = {3612--3628}, year = {2012}, month = mar, doi = {10.1523/JNEUROSCI.4010-11.2012}, publisher = {Society for Neuroscience}, issn = {0270-6474}, url = {https://www.jneurosci.org/content/32/11/3612}, journal = {Journal of Neuroscience}, } - CurrOpN
 Probabilistic vs. non-probabilistic approaches to the neurobiology of perceptual decision-makingJan Drugowitsch, and Alexandre PougetCurrent Opinion in Neurobiology, Dec 2012Decision making
Probabilistic vs. non-probabilistic approaches to the neurobiology of perceptual decision-makingJan Drugowitsch, and Alexandre PougetCurrent Opinion in Neurobiology, Dec 2012Decision makingOptimal binary perceptual decision making requires accumulation of evidence in the form of a probability distribution that specifies the probability of the choices being correct given the evidence so far. Reward rates can then be maximized by stopping the accumulation when the confidence about either option reaches a threshold. Behavioral and neuronal evidence suggests that humans and animals follow such a probabilitistic decision strategy, although its neural implementation has yet to be fully characterized. Here we show that that diffusion decision models and attractor network models provide an approximation to the optimal strategy only under certain circumstances. In particular, neither model type is sufficiently flexible to encode the reliability of both the momentary and the accumulated evidence, which is a pre-requisite to accumulate evidence of time-varying reliability. Probabilistic population codes, by contrast, can encode these quantities and, as a consequence, have the potential to implement the optimal strategy accurately.
@article{curropn2012, title = {Probabilistic vs. non-probabilistic approaches to the neurobiology of perceptual decision-making}, journal = {Current Opinion in Neurobiology}, volume = {22}, number = {6}, pages = {963-969}, year = {2012}, month = dec, note = {Decision making}, issn = {0959-4388}, doi = {10.1016/j.conb.2012.07.007}, url = {https://www.sciencedirect.com/science/article/pii/S095943881200116X}, author = {Drugowitsch, Jan and Pouget, Alexandre}, }



2010
- IWLCS
 Learning Classifier Systems: 11th International Workshop, IWLCS 2008, Atlanta, GA, USA, July 13, 2008, and 12th International Workshop, IWLCS 2009, Montreal, QC, Canada, July 9, 2009, Revised Selected PapersNov 2010
Learning Classifier Systems: 11th International Workshop, IWLCS 2008, Atlanta, GA, USA, July 13, 2008, and 12th International Workshop, IWLCS 2009, Montreal, QC, Canada, July 9, 2009, Revised Selected PapersNov 2010@book{iwlcs2011, title = {Learning Classifier Systems: 11th International Workshop, IWLCS 2008, Atlanta, GA, USA, July 13, 2008, and 12th International Workshop, IWLCS 2009, Montreal, QC, Canada, July 9, 2009, Revised Selected Papers}, editors = {Jaume Bacardit and Will Browne and Jan Drugowitsch and Ester Bernadó-Mansilla and Martin V. Butz}, publisher = {Springer Berlin, Heidelberg}, doi = {10.1007/978-3-642-17508-4}, year = {2010}, month = nov, isbn = {978-3-642-17507-7}, url = {https://doi.org/10.1007/978-3-642-17508-4}, series = {Lecture Notes in Computer Science}, } - NatNeuro
 Quick thinking: perceiving in a tenth of a blink of an eyeJan Drugowitsch, and Alexandre PougetNature Neuroscience, Mar 2010
Quick thinking: perceiving in a tenth of a blink of an eyeJan Drugowitsch, and Alexandre PougetNature Neuroscience, Mar 2010What is the minimal sensory processing time before we can make a decision about a stimulus? A study now reports that, for simple perceptual decisions, this can take as little as 30 ms.
@article{natneuro2010, title = {Quick thinking: perceiving in a tenth of a blink of an eye}, journal = {Nature Neuroscience}, volume = {13}, number = {3}, pages = {279--280}, year = {2010}, month = mar, doi = {10.1038/nn0310-279}, url = {https://doi.org/10.1038/nn0310-279}, author = {Drugowitsch, Jan and Pouget, Alexandre}, }


2008
- IWLCS
 Analysis and Improvements of the Classifier Error Estimate in XCSFDaniele Loiacono, Jan Drugowitsch, Alwyn Barry, and Pier Luca LanziIn Learning Classifier Systems, Mar 2008
Analysis and Improvements of the Classifier Error Estimate in XCSFDaniele Loiacono, Jan Drugowitsch, Alwyn Barry, and Pier Luca LanziIn Learning Classifier Systems, Mar 2008The estimation of the classifier error plays a key role in accuracy-based learning classifier systems. In this paper we study the current definition of the classifier error in XCSF and discuss the limitations of the algorithm that is currently used to compute the classifier error estimate from online experience. Subsequently, we introduce a new definition for the classifier error and apply the Bayes Linear Analysis framework to find a more accurate and reliable error estimate. This results in two incremental error estimate update algorithms that we compare empirically to the performance of the currently applied approach. Our results suggest that the new estimation algorithms can improve the generalization capabilities of XCSF, especially when the action-set subsumption operator is used.
@inproceedings{iwlcsbook2008b, author = {Loiacono, Daniele and Drugowitsch, Jan and Barry, Alwyn and Lanzi, Pier Luca}, editor = {Bacardit, Jaume and Bernad{\'o}-Mansilla, Ester and Butz, Martin V. and Kovacs, Tim and Llor{\`a}, Xavier and Takadama, Keiki}, title = {Analysis and Improvements of the Classifier Error Estimate in XCSF}, booktitle = {Learning Classifier Systems}, year = {2008}, publisher = {Springer Berlin Heidelberg}, address = {Berlin, Heidelberg}, pages = {117--135}, isbn = {978-3-540-88138-4}, doi = {10.1007/978-3-540-88138-4_7}, } -
 Design and Analysis of Learning Classifier Systems: A Probabilistic ApproachJan DrugowitschMay 2008
Design and Analysis of Learning Classifier Systems: A Probabilistic ApproachJan DrugowitschMay 2008@book{lcsbook2008, author = {Drugowitsch, Jan}, title = {Design and Analysis of Learning Classifier Systems: A Probabilistic Approach}, publisher = {Springer Berlin, Heidelberg}, doi = {10.1007/978-3-540-79866-8}, isbn = {978-3-540-79866-8}, series = {Studies in Computational Intelligence}, year = {2008}, month = may, } - ML
 A formal framework and extensions for function approximation in learning classifier systemsJan Drugowitsch, and Alwyn M. BarryMachine Learning, Jan 2008
A formal framework and extensions for function approximation in learning classifier systemsJan Drugowitsch, and Alwyn M. BarryMachine Learning, Jan 2008Learning Classifier Systems (LCS) consist of the three components: function approximation, reinforcement learning, and classifier replacement. In this paper we formalize the function approximation part, by providing a clear problem definition, a formalization of the LCS function approximation architecture, and a definition of the function approximation aim. Additionally, we provide definitions of optimality and what conditions need to be fulfilled for a classifier to be optimal. As a demonstration of the usefulness of the framework, we derive commonly used algorithmic approaches that aim at reaching optimality from first principles, and introduce a new Kalman filter-based method that outperforms all currently implemented methods, in addition to providing further insight into the probabilistic basis of the localized model that a classifier provides. A global function approximation in LCS is achieved by combining the classifier’s localized model, for which we provide a simplified approach when compared to current LCS, based on the Maximum Likelihood of a combination of all classifiers. The formalizations in this paper act as the foundation of a currently actively developed formal framework that includes all three LCS components, promising a better formal understanding of current LCS and the development of better LCS algorithms.
@article{ml2008, title = {A formal framework and extensions for function approximation in learning classifier systems}, journal = {Machine Learning}, volume = {70}, number = {1}, pages = {45--88}, year = {2008}, month = jan, doi = {10.1007/s10994-007-5024-8}, url = {https://doi.org/10.1007/s10994-007-5024-8}, author = {Drugowitsch, Jan and Barry, Alwyn M.}, } - IWLCS
 A Principled Foundation for LCSJan Drugowitsch, and Alwyn M. BarryIn Learning Classifier Systems, Jan 2008
A Principled Foundation for LCSJan Drugowitsch, and Alwyn M. BarryIn Learning Classifier Systems, Jan 2008In this paper we promote a new methodology for designing LCS that is based on first identifying their underlying model and then using standard machine learning methods to train this model. This leads to a clear identification of the LCS model and makes explicit the assumptions made about the data, as well as promises advances in the theoretical understanding of LCS through transferring the understanding of the applied machine learning methods to LCS. Additionally, it allows us, for the first time, to give a formal and general, that is, representation-independent, definition of the optimal set of classifiers that LCS aim at finding. To demonstrate the feasibility of the proposed methodology we design a Bayesian LCS model by borrowing concepts from the related Mixtures-of-Experts model. The quality of a set of classifiers and consequently also the optimal set of classifiers is defined by the application of Bayesian model selection, which turns finding this set into a principled optimisation task. Using a simple Pittsburgh-style LCS, a set of preliminary experiments demonstrate the feasibility of this approach.
@inproceedings{iwlcsbook2008a, author = {Drugowitsch, Jan and Barry, Alwyn M.}, editor = {Bacardit, Jaume and Bernad{\'o}-Mansilla, Ester and Butz, Martin V. and Kovacs, Tim and Llor{\`a}, Xavier and Takadama, Keiki}, title = {A Principled Foundation for LCS}, booktitle = {Learning Classifier Systems}, year = {2008}, publisher = {Springer Berlin Heidelberg}, address = {Berlin, Heidelberg}, pages = {77--95}, isbn = {978-3-540-88138-4}, doi = {10.1007/978-3-540-88138-4_5}, }




2007
-
 Generalised mixtures of experts, independent expert training, and learning classifier systemsJan Drugowitsch, and Alwyn M. BarryApr 2007
Generalised mixtures of experts, independent expert training, and learning classifier systemsJan Drugowitsch, and Alwyn M. BarryApr 2007We present a generalisation to the Mixtures of Experts model that introduces prior localisation of the experts as part of the model structure, and as such relates them strongly to the evolutionary computation ML method known as Learning Classifier Systems. While the introduced generalisation allows specification of more complex localisation patterns, identifying good models becomes more difficult. We approach this tradeoff by introducing a new training schema that makes fitting a single model computationally less demanding and shifts the importance to searching the space of possible model structures, guided by approximate variational Bayesian inference to fit the model and find the model evidence. We demonstrate model search for simple non-linear curve fitting tasks by sampling from the model posterior, as a proof-of-concept alternative to the genetic algorithm used in Learning Classifier Systems for that purpose.
@techreport{csbu-2007-02, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {Generalised mixtures of experts, independent expert training, and learning classifier systems}, institution = {Department of Computer Science, University of Bath}, address = {Bath, UK}, number = {CSBU-2007-02}, year = {2007}, month = apr, } -
 Learning classifier systems from first principles: a probabilistic reformulation of learning classifier systems from the perspective of machine learningJan DrugowitschUniversity of Bath, Aug 2007
Learning classifier systems from first principles: a probabilistic reformulation of learning classifier systems from the perspective of machine learningJan DrugowitschUniversity of Bath, Aug 2007Learning Classifier Systems (LCS) are a family of rule-based machine learning methods. They aim at the autonomous production of potentially humanreadable results that are the most compact generalised representation whilst also maintaining high predictive accuracy, with a wide range of application areas, such as autonomous robotics, economics, and multi-agent systems. Their design is mainly approached heuristically and, even though their performance is competitive in regression and classification tasks, they do not meet their expected performance in sequential decision tasks despite being initially designed for such tasks. It is out contention that improvement is hindered by a lack of theoretical understanding of their underlying mechanisms and dy namics. To improve this understanding, our work proposes a new methodology for their design that centres on the model they use to represent the problem structure, and subsequently applies standard machine learning methods to train this model. The LCS structure is commonly a set of rules, resulting in a parametric model that combines a set of localised models, each representing one rule. This leads to a general definition of the optimal set of rules as being the one whose model represents the data best and at a minimum complexity, and hence an increased theoretical understanding of LCS. Consequently, LCS training reduces to searching and evaluating this set of rules, for which we introduce and apply several standard methods that are shown to be closely related to current LCS implementations. The benefit of taking this approach is not only a new view on LCS, and the transfer of the formal basis of the applied methods to the analysis of LCS, but also the first general definition for what it means for a set of rules to be optimal. The work promises advances in several areas, such as developing new LCS implementations with performance guarantees, to improve their performance, and foremost their theoretical understanding.
@phdthesis{thesis2007, author = {Drugowitsch, Jan}, title = {Learning classifier systems from first principles: a probabilistic reformulation of learning classifier systems from the perspective of machine learning}, school = {University of Bath}, address = {Bath, UK}, year = {2007}, month = aug, } - GECCO
 Mixing Independent ClassifiersJan Drugowitsch, and Alwyn M. BarryIn Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation, London, England, Aug 2007
Mixing Independent ClassifiersJan Drugowitsch, and Alwyn M. BarryIn Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation, London, England, Aug 2007In this study we deal with the mixing problem, which concerns combining the prediction of independently trained local models to form a global prediction. We deal with it from the perspective of Learning Classifier Systems where a set of classifiers provide the local models. Firstly, we formalise the mixing problem and provide both analytical and heuristic approaches to solving it. The analytical approaches are shown to not scale well with the number of local models, but are nevertheless compared to heuristic models in a set of function approximation tasks. These experiments show that we can design heuristics that exceed the performance of the current state-of-the-art Learning Classifier System XCS, and are competitive when compared to analytical solutions. Additionally, we provide an upper bound on the prediction errors for the heuristic mixing approaches.
@inproceedings{gecco2007b, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {Mixing Independent Classifiers}, year = {2007}, isbn = {9781595936974}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/1276958.1277278}, doi = {10.1145/1276958.1277278}, booktitle = {Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation}, pages = {1596–1603}, numpages = {8}, keywords = {information fusion, learning classifier systems}, location = {London, England}, series = {GECCO '07}, } - GECCO
 A Principled Foundation for LCSJan Drugowitsch, and Alwyn M. BarryIn Proceedings of the 9th Annual Conference Companion on Genetic and Evolutionary Computation, London, United Kingdom, Aug 2007
A Principled Foundation for LCSJan Drugowitsch, and Alwyn M. BarryIn Proceedings of the 9th Annual Conference Companion on Genetic and Evolutionary Computation, London, United Kingdom, Aug 2007In this paper we explicitly identify the probabilistic model underlying LCS by linking it to a generalisation of the common Mixture-of-Experts model. Having an explicit representation of the model not only puts LCS on a strong statistical foundation and identifies the assumptions that the model makes about the data, but also allows us to use off-the-shelf training methods to train it. We show how to exploit this advantage by embedding the LCS model into a fully Bayesian framework that results in an objective function for a set of classifiers, effectively turning the LCS training into a principled optimisation task. A set of preliminary experiments demonstrate the feasibility of this approach.
@inproceedings{gecco2007a, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {A Principled Foundation for LCS}, year = {2007}, isbn = {9781595936981}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/1274000.1274056}, doi = {10.1145/1274000.1274056}, booktitle = {Proceedings of the 9th Annual Conference Companion on Genetic and Evolutionary Computation}, pages = {2675–2680}, numpages = {6}, keywords = {independently trained local models, mixtures-of-experts, learning classifier systems, xms, bayesian model selection}, location = {London, United Kingdom}, series = {GECCO '07}, }




2006
-
 A Formal Framework and Extensions for Function Approximation in Learning Classifier SystemsJan Drugowitsch, and Alwyn M. BarryJan 2006
A Formal Framework and Extensions for Function Approximation in Learning Classifier SystemsJan Drugowitsch, and Alwyn M. BarryJan 2006In this paper we introduce part of a formal framework for Learning Classifier Systems (LCS) which, as a whole, aims at incorporating all components of LCS: function approximation, reinforcement learning and classifier replacement. The part introduced here concerns function approximation, and provides a formal problem definition, a formalisation of the LCS function approximation architecture, and a definition of the approximation aim. Additionally, we provide definitions of optimality and what conditions need to be fulfilled for a classifier to be optimal. Furthermore, as a demonstration of the usefulness of the framework, we derive commonly used algorithmic approaches that aim at reaching optimality from first principles, and introduce a new Kalman filter-based method that outperforms all currently implemented methods. How to mix classifiers to reach an overall approximation is simplified when compared to current LCS, and is justified by the Maximum Likelihood Estimate of a combination of all classifiers.
@techreport{csbu-2006-01, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {A Formal Framework and Extensions for Function Approximation in Learning Classifier Systems}, institution = {Department of Computer Science, University of Bath}, address = {Bath, UK}, number = {CSBU-2006-01}, year = {2006}, month = jan, issn = {1740-9497}, } -
 A Formal Framework for Reinforcement Learning with Function Approximation in Learning Classifier SystemsJan Drugowitsch, and Alwyn M. BarryJan 2006
A Formal Framework for Reinforcement Learning with Function Approximation in Learning Classifier SystemsJan Drugowitsch, and Alwyn M. BarryJan 2006To fully understand the properties of Accuracy-based Learning Classifier Systems, we need a formal framework that captures all components of classifier systems, that is, function approximation, reinforcement learning, and classifier replacement, and permits the modelling of them separately and in their interaction. In this paper we extend our previous work on function approximation to reinforcement learning and its interaction between reinforcement learning and function approximation. After giving an overview and derivations for common reinforcement learning methods from first principles, we show how they apply to Learning Classifier Systems. At the same time, we present a new algorithm that is expected to outperform all current methods, discuss the use of XCS with gradient descent and TD(λ), and given an in-depth discussion on how to study the convergence of Learning Classifier Systems with a time-invariant population.
@techreport{csbu-2006-02, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {A Formal Framework for Reinforcement Learning with Function Approximation in Learning Classifier Systems}, institution = {Department of Computer Science, University of Bath}, address = {Bath, UK}, number = {CSBU-2006-02}, year = {2006}, month = jan, issn = {1740-9497}, } - IWLCS
 Improving classifier error estimate in XCSFJan Drugowitsch, and Alwyn M. BarryIn The Ninth International Workshop on Learning Classifier Systems, IWLCS-2006, Jan 2006
Improving classifier error estimate in XCSFJan Drugowitsch, and Alwyn M. BarryIn The Ninth International Workshop on Learning Classifier Systems, IWLCS-2006, Jan 2006In this paper we explicitly identify the probabilistic model underlying LCS by linking it to a generalisation of the common Mixture-of-Experts model. Having an explicit representation of the model not only puts LCS on a strong statistical foundation and identifies the assumptions that the model makes about the data, but also allows us to use off-the-shelf training methods to train it. We show how to exploit this advantage by embedding the LCS model into a fully Bayesian framework that results in an objective function for a set of classifiers, effectively turning the LCS training into a principled optimisation task. A set of preliminary experiments demonstrate the feasibility of this approach.
@inproceedings{iwlcs2006, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {Improving classifier error estimate in XCSF}, year = {2006}, booktitle = {The Ninth International Workshop on Learning Classifier Systems, IWLCS-2006}, pages = {1-16}, series = {IWLCS '06}, } -
 Mixing Independent ClassifiersJan Drugowitsch, and Alwyn M. BarryNov 2006
Mixing Independent ClassifiersJan Drugowitsch, and Alwyn M. BarryNov 2006In this study we deal with the mixing problem, which concerns combining the prediction of independently trained local models to a global prediction. We deal with it from the perspective of Learning Classifier Systems where a set of classifiers provide the local models. Firstly, we formalise the mixing problem and provide both analytical and heuristic approaches to solving it. The analytical approaches are shown to not scale well with the number of local models, but are nevertheless compared to heuristic models in a set of function approximation tasks. These experiments show that we can design heuristics that exceed the performance of the current state-of-the-art Learning Classifier System XCS, and are competitive when compared to analytical solutions. Additionally, we provide an upper bound on the prediction errors for the heuristic mixing approaches.
@techreport{csbu-2006-13, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {Mixing Independent Classifiers}, institution = {Department of Computer Science, University of Bath}, address = {Bath, UK}, number = {CSBU-2006-13}, year = {2006}, month = nov, issn = {1740-9497}, } -
 Towards Convergence of Learning Classifier Systems Value IterationJan Drugowitsch, and Alwyn M. BarryIn Evolutionary Computation Workshop at the European Conference of Artificial Intelligence (ECAI), Nov 2006
Towards Convergence of Learning Classifier Systems Value IterationJan Drugowitsch, and Alwyn M. BarryIn Evolutionary Computation Workshop at the European Conference of Artificial Intelligence (ECAI), Nov 2006In this paper we are extending previous work on analysing Learning Classifier Systems (LCS) in the reinforcement learning framework to deepen the theoretical analysis of Value Iteration with LCS function approximation. After introducing the formal framework and some mathematical preliminaries we demonstrate convergence of the algorithm for fixed classifier mixing weights, and show that if the weights are not fixed, the choice of the mixing function is significant. Furthermore, we discuss accuracybased mixing and outline a proof that shows convergence of LCS Value Iteration with an accuracy-based classifier mixing. This work is a significant step towards convergence of accuracy-based LCS that use Q-Learning as the reinforcement learning component.
@inproceedings{ecai2006, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {Towards Convergence of Learning Classifier Systems Value Iteration}, year = {2006}, booktitle = {Evolutionary Computation Workshop at the European Conference of Artificial Intelligence (ECAI)}, pages = {1-5}, series = {ECAI '06}, }





2005
-
 Integrating Life-Like Action Selection into Cycle-Based Agent Simulation EnvironmentsJoanna J Bryson, Tristan J Caulfield, and Jan DrugowitschIn Proceedings of Agent 2005: Generative Social Processes, Models, and Mechanisms, Argonne National Laboratory, Nov 2005
Integrating Life-Like Action Selection into Cycle-Based Agent Simulation EnvironmentsJoanna J Bryson, Tristan J Caulfield, and Jan DrugowitschIn Proceedings of Agent 2005: Generative Social Processes, Models, and Mechanisms, Argonne National Laboratory, Nov 2005Standardised simulation platforms such as RePast, Swarm, MASON and NetLogo are making Agent-Based Modelling accessible to ever-widening audiences. Some proportion of these modellers have good reason to want their agents to express relatively complex behaviour, or they may wish to describe their agents’ actions in terms of real time. Agents of increasing complexity may often be better (more simply) described using hierarchical constructs which express the priorities and goals of their actions, and the contexts in which sets of actions may be applicable (Bryson, 2003a). Describing an agent’s behaviour clearly and succinctly in this way might seem at odds with the iterative, cycle-based nature of most simulation platforms. Because each agent is known to act in lock-step synchrony with the others, describing the individual’s behaviour in terms of fluid, coherent long-term plans may seem difficult. In this paper we describe how an action-selection system designed for more conventionallyhumanoid AI such as robotics and virtual reality can be incorporated into a cycle-based ABM simulation platform. We integrate a Python-language version of the action selection for Bryson’s Behavior Oriented Design (BOD) into a fairly standard cycle-based simulation platform, MASON (Luke et al., 2003). The resulting system is currently being used as a research platform in our group, and has been used for laboratories in the European Agent Systems Summer School.
@inproceedings{agent2005, author = {Bryson, Joanna J and Caulfield, Tristan J and Drugowitsch, Jan}, title = {Integrating Life-Like Action Selection into Cycle-Based Agent Simulation Environments}, year = {2005}, booktitle = {Proceedings of Agent 2005: Generative Social Processes, Models, and Mechanisms}, editor = {North, Michael and Sallach, David L. and Macal, Charles}, location = {Argonne National Laboratory}, pages = {76-82}, } - GECCO
 XCS with Eligibility TracesJan Drugowitsch, and Alwyn M. BarryIn Proceedings of the 7th Annual Conference on Genetic and Evolutionary Computation, Washington DC, USA, Nov 2005
XCS with Eligibility TracesJan Drugowitsch, and Alwyn M. BarryIn Proceedings of the 7th Annual Conference on Genetic and Evolutionary Computation, Washington DC, USA, Nov 2005The development of the XCS Learning Classifier System has produced a robust and stable implementation that performs competitively in direct-reward environments. Although investigations in delayed-reward (i.e. multi-step) environments have shown promise, XCS still struggles to efficiently find optimal solutions in environments with long action-chains. This paper highlights the strong relation of XCS to reinforcement learning and identifies some of the major differences. This makes it possible to add Eligibility Traces to XCS, a method taken from reinforcement learning to update the prediction of the whole action-chain on each step, which should cause prediction update to be faster and more accurate. However, it is shown that the discrete nature of the condition representation of a classifier and the operation of the genetic algorithm cause traces to propagate back incorrect prediction values and in some cases results in a decrease of system performance. As a result further investigation of the existing approach to generalisation is proposed.
@inproceedings{gecco2005, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {XCS with Eligibility Traces}, year = {2005}, isbn = {1595930108}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/1068009.1068322}, doi = {10.1145/1068009.1068322}, booktitle = {Proceedings of the 7th Annual Conference on Genetic and Evolutionary Computation}, pages = {1851–1858}, numpages = {8}, keywords = {eligibility traces, q-learning, XCS, LCS, temporal-difference learning}, location = {Washington DC, USA}, series = {GECCO '05}, } -
 XCS with Eligibility TracesJan Drugowitsch, and Alwyn M. BarryJan 2005
XCS with Eligibility TracesJan Drugowitsch, and Alwyn M. BarryJan 2005The development of the XCS Learning Classifier System has produced a robust and stable implementation that performs competitively in direct–reward environments. Although investigations in delayed–reward (i.e. multi–step) environments have shown promise, XCS still struggles to efficiently find optimal solutions in environments with long action–chains. This paper highlights the strong relation of XCS to reinforcement learning and identifies some of the major differences. This makes it possible to add Eligibility Traces to XCS, a method taken from reinforcement learning to update the prediction of the whole action–chain on each step, which should cause prediction update to be faster and more accurate. However, it is shown that the discrete nature of the condition representation of a classifier and the operation of the genetic algorithm cause traces to propagate back incorrect prediction values and in some cases results in a decrease of system performance. As a result further investigation of the existing approach to generalisation is proposed.
@techreport{csbu-2005-1, author = {Drugowitsch, Jan and Barry, Alwyn M.}, title = {XCS with Eligibility Traces}, institution = {Department of Computer Science, University of Bath}, address = {Bath, UK}, number = {CSBU-2005-01}, year = {2005}, month = jan, issn = {1740-9497}, }


